Analysis of NVidia's Unified Virtual Memory Roadmap Disappearance & an ARM Future
Posted on
After offering reddit's computer hardware & buildapc sub-reddits the opportunity to ask us about our nVidia GTC keynote coverage, an astute reader ("asome132") noticed that the new Pascal roadmap had a key change: Maxwell's "unified virtual memory" line-item had been replaced with a very simple, vague "DirectX 12" item. We investigated the change while at GTC, speaking to a couple of CUDA programmers and Maxwell architecture experts; I sent GN's own CUDA programmer and 30+ year programming veteran, Jim Vincent, to ask nVidia engineers about the change in the slide deck. Below includes the official stance along with our between-the-lines interpretation and analysis.

In this article, we'll look at the disappearance of "Unified Virtual Memory" from nVidia's roadmap, discuss an ARM/nVidia future that challenges existing platforms, and look at NVLink's intentions and compatible platforms.
(This article has significant contributions from GN Staff Writer & CUDA programmer Jim Vincent).
First Off: What is Unified Virtual Memory as it pertains to Maxwell?
Maxwell's initially-promised (also on K1) Unified Virtual Memory would effectively pool the GPU and system memory into a single addressable space from the programmer's perspective; the CUDA programming language (version 6, presently) supports this in full, but it's a matter of GPU architecture and system platforms enabling it. The beginnings of this were seen in CUDA 4. The TEGRA K1 -- an ARM CPU with Kepler graphics -- also supports unified memory and will likely continue when K1 is inevitably upgraded to a Maxwell part in the future.
With unified virtual memory (we'll call this "UVM" going forward, for ease), a CUDA programmer does not have to make explicit copy operations to move pertinent data from system memory to the GPU's memory. This makes code simpler to write (fewer lines, less work) and allows the GPU and its architecture to take over the copy task, eliminating explicit copy/pin operations on behalf of the programmer.
They aren't really the same thing, but you might have noticed that AMD's APUs have unified memory between the CPU and IGP (a bit different, since there's no on-card memory - or card, for that matter) and that Intel will also be making similar offers with its platforms. Again, it's not the same thing, but my point is to underscore the fact that unified memory addressing and pooling/access are a trending engineering topic within the semiconductor manufacturing companies right now.
UVM as nVidia prescribed it takes memory management out of the hands of the programmer and moves it to the system; it does not eliminate the need for copies between system and GPU memory, but eliminates the demand for a human to do so. I just wanted to reiterate that for point of clarity. On x86, nVidia's CUDA hides the non-unified memory by implementing the copies and data integrity automatically into the CUDA language implementation, which frees the programmer up to perform other tasks. Everything is still copied back-and-forth between the CPU memory and GPU memory via the PCI Express bus. The code will function unchanged on TEGRA's K1 and the IBM Power CPU, it will just be more efficient on these platforms because copies aren't necessary since the memory is shared (which is much faster). This brings the potential for severe market fragmentation in the future -- even for gamers -- but I'll talk about that in a bit.

For any CUDA programmers in the audience, this is what the difference looks like.
OK. So where'd this go on the recent nVidia Pascal roadmap?
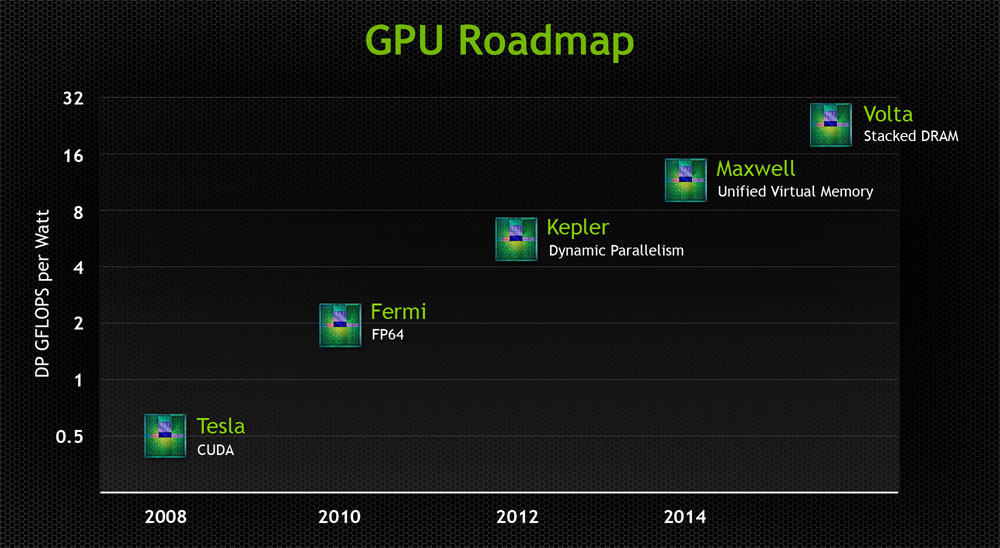

Above you will find two roadmaps. One is older, showing the trend toward Maxwell as released quite a while ago. The other is from our GTC coverage last week. Look at Maxwell to spot the difference.
We'll talk about NVLink and UVM in the same section below.
In order to leverage UVM in its present state, the GPU must be coupled with either an IBM Power CPU (server architecture) or an nVidia TEGRA chip (like the K1), which is effectively an ARM CPU with an nVidia IGP. This will extend to Maxwell and Pascal married to their ARM CPU. In speaking with an nVidia Maxwell CUDA programmer at GTC, it sounds like "true Unified Virtual Memory would require NVLink." I'll base the rest of my analysis on this statement.
NVLink is nVidia's new physical, on-board interface that is meant to replace PCI-e to bypass bandwidth limitations. I already wrote about this here. The short of it is that NVLink is a DMA+-enabled interface that allows unified memory addressing between the CPU and GPU; it also allows what is called "second-generation cache coherency" between the caches. Cache coherence is a means to manage numerous copies of the same instruction that is found in multiple caches within a system sharing memory between processors. If there's a piece of data (an instruction operand) in multiple locations within memory and cache (to speed things up for the various multiprocessors requesting it), and that piece of data is changed, cache coherence ensures the change is applied to all instances of the data in all caches and memory. It is a means to propagate change. To clarify: This isn't necessarily an "nVidia thing" as it can be found in other modern architectures.
So NVLink does all of this and allows what nVidia called "true unified virtual memory." Along with other "optimizations" that weren't delved into, the NVLink interface was reported as "increasing throughput/bandwidth and performance by 5x-12x over PCI-e 3.0."

NVLink's Focus on Supercomputing, Some TEGRA Thoughts
It is worth noting that NVLink is more immediately beneficial to supercomputing platforms that would prosper from high-bandwidth interfaces, and isn't necessarily targeted at gamers in the immediate future. That doesn't preclude nVidia from wanting to move in that direction, though; most new everything in the industry is introduced to
Allow me to further highlight that NVLink is explicitly advertised as a "[tight] coupling of IBM POWER CPUs with nVidia TESLA GPUs" and that nVidia calls NVLink a "high-speed interconnect [that] will enable the tightly-coupled systems that present a path to highly energy-efficient and scalable exascale supercomputers, running at 1x10^18 floating point operations per second." So, again, NVLink isn't meant for most of us. But that doesn't mean we can't still talk about why UVM vanished from the roadmap.
If UVM to its fullest potential requires NVLink -- a physical interface on the board -- and NVLink requires an IBM Power CPU or TEGRA chip, we won't be seeing UVM on mainstream platforms for quite a while. Does that really mean anything bad for gamers? No, not really - not immediately, because we're not the right audience; our GPUs rarely even saturate existing PCI-e interfaces when it comes to the standard encoding or gaming workloads. What it does mean, though, is that nVidia removed it from the roadmap to likely reduce confusion about why we're not seeing UVM globally. That doesn't mean nVidia wouldn't love to make UVM (and NVLink) a possibility on mainstream boards, but that's unlikely to happen. These moves also have curious implications for the future of the CPU market -- perhaps even competition against x86 in mainstream desktop platforms. More on that in a minute.
At a dinner with nVidia, we were presented the opportunity to ask questions about the keynote from that day. The question from GN's Jim Vincent was pretty simple: "When will Intel support NVLink?" We got a bit of a laugh, then the conversation turned elsewhere. I asked again later, and from how I read the responses, it sounds like it's more of a matter of Intel being willing (or, rather, unwilling) to work with nVidia on this. This extends to Intel's x86 server platforms, so when I talk about inclusion of NVLink on Intel, it doesn't just mean what most of us are using in gaming PCs.
Reading Between the Lines
Allow me to first restate an important point: NVLink is meant for supercomputing in its current form.

Intel sees nVidia as competition. They're a threat. NVidia's coupling with ARM is the most immediate reason for this, but a slow crawl of nVidia outward to other platforms in the consumer space (they don't just do GTX GPUs anymore) is reason for Intel to feel concerned.
Intel and AMD largely control the motherboard marketplace when it comes down to their verticals. Opteron and Xeon have reference designs (as also seen in mainstream/enthusiast boards) that are followed closely. It's pretty unlikely that AMD would ever integrate with NVLink for the obvious reason of competition. Intel almost certainly sees nVidia as a threat in at least some market spaces moving forward. In order for NVLink to work on one of the major x86 platforms, like an Intel chip, nVidia and Intel would have to make a deal to hook NVLink into the platform. Our conversations with nVidia indicate that Intel has no interest or has remained silent on this.
NVidia's TEGRA chip is, again, coupled with ARM, who have been a deeply-lodged thorn in Intel's side for a number of years now. ARM dominates many aspects of the mobile and low-power computing marketplaces that Intel has desperately been working toward serving.
On the other side of the chip, Intel has been pushing to gain traction with its own graphics solutions (which have slowly-but-surely gained relevance in some applications). Pointing both of these facts out, it seems unlikely to me that Intel would want to work with nVidia in unifying memory in the manner described above; it also seems unlikely that Intel would want to change board design to accommodate NVLink, which is a relatively untested interface with very specific use-case applications in its current form. And from a company seen as a competitor in many ways.

And so "Unified Virtual Memory" has been removed from the updated roadmap, silently replaced with an incredibly vague, buzz-wordy "DirectX 12" line item that's intended to appeal to the "average" onlooker. NVidia is investing heavy resources into its D3D12 partnership and has been getting aggressive about invalidating AMD's Mantle; this is something you'll learn more about from us on Monday, when we'll be talking about a recent press conference.
And here's where I put myself out there: I've got a sneaking suspicion that we could see TEGRA slowly making attempts at land grabs in other spaces. Many of the nVidia technologies covered at GTC in programming panels are compatible with the company's K1 and upcoming Maxwell TEGRA processors, along with already-stated Power processors. I'm curious to see if TEGRA makes an attempt to move into some sort of more "traditional" market outside of mobile, like the SFF / HTPC spaces. It's becoming a very powerful, competitive chip (though has some downsides within its vertical presently, like a higher TDP than other offerings) that'd do well in something like a NUC form factor.
It is likely that nVidia envisions an ARM + nVidia future, raising the question as to whether Windows (outside of RT) will be supported on ARM going forward. NVidia does not own the required x86 licenses from AMD and Intel to move into the space, so continued ARM/nV coupling makes sense. Still, Windows RT runs on ARM devices and Microsoft has heavily-invested itself into mobile platforms going forward. Linux and SteamOS are also gaining traction - if they continue to do so, ARM/nVidia could be an alternative to x86 in the very far future. If this happens, it is likely that derivations of architecture would resemble something like this:
1 – x86 running some derivative of PCI-e with non-unified memory access through NVidia.
2 – x86 running Intel-only CPU/GPU supporting their version of unified memory access.
3 – x86 running AMD only CPU/GPU (APU) supporting AMD’s version of unified memory access.
4 – ARM coupled with NVidia CPU/GPU with unified memory access
5 – ARM coupled with AMD CPU/GPU with their unified memory access.
6 – ARM Samsung – anyone's guess.
7 – ARM Apple – anyone's guess.
8 – ARM – all the other ARM manufactures with non-NVidia non-AMD GPU’s (exiting mainstream computing).
I won't make any predictions because I can't confidently speak to the future of TEGRA, but I did want to highlight the potential for the chip to make moves into other marketplaces. The above showcases some possible enumerations if competition emboldens, but again, such derivations would be in the far future and would require many variables to happen -- like nVidia's success in these spaces, which is certainly not guaranteed. A lot of this will also hinge on Microsoft and their dedication to the RT (or equivalent) platforms. As we understand it, Windows RT has free licensing on ARM devices with 9" screens or smaller, so it's curious whether Microsoft might port DirectX to help nVidia; they've already worked very closely with nVidia to develop Dx12 (check the site on Monday for that announcement), so further partnership could happen. Surface RT ran on a TEGRA 3, to put things into perspective.
I'm told by our resident programming expert (that'd be Jim Vincent) that "porting game engines from x86 to TEGRA K1 and higher would probably not be that hard [relatively]. There's no DirectX, but you have OpenGL and C++ (the CPU side) that compiles just fine on ARM."
We're trying to connect with IBM to get access to some whitepapers so we can provide more confident analysis on these topics.
Let us know if you've got any other article topics you'd like to see us tackle or ask manufacturers about! Thoughts on this, everyone?
- Writing, Analysis: Steve "Lelldorianx" Burke.
- Expert Analysis, Research: Jim "Neutron" Vincent.