NVidia Turing Architecture Technical Deep-Dive: SM Rework, Big Turing, and INT vs. FP
Posted on
NVidia’s Turing architecture has entered the public realm, alongside an 83-page whitepaper, and is now ready for technical detailing. We have spoken with several nVidia engineers over the past few weeks, attended the technical editor’s day presentations, and have read through the whitepaper – there’s a lot to get through, so we will be breaking this content into pieces with easily navigable headers.
Turing is a modified Volta at its core, which is a heavily modified Pascal. Core architecture isn’t wholly unrecognizable between Turing and Pascal – you’d be able to figure out that they’re from the same company – but there are substantive changes within the Turing core.
Major Changes in Turing vs. Pascal Architecture
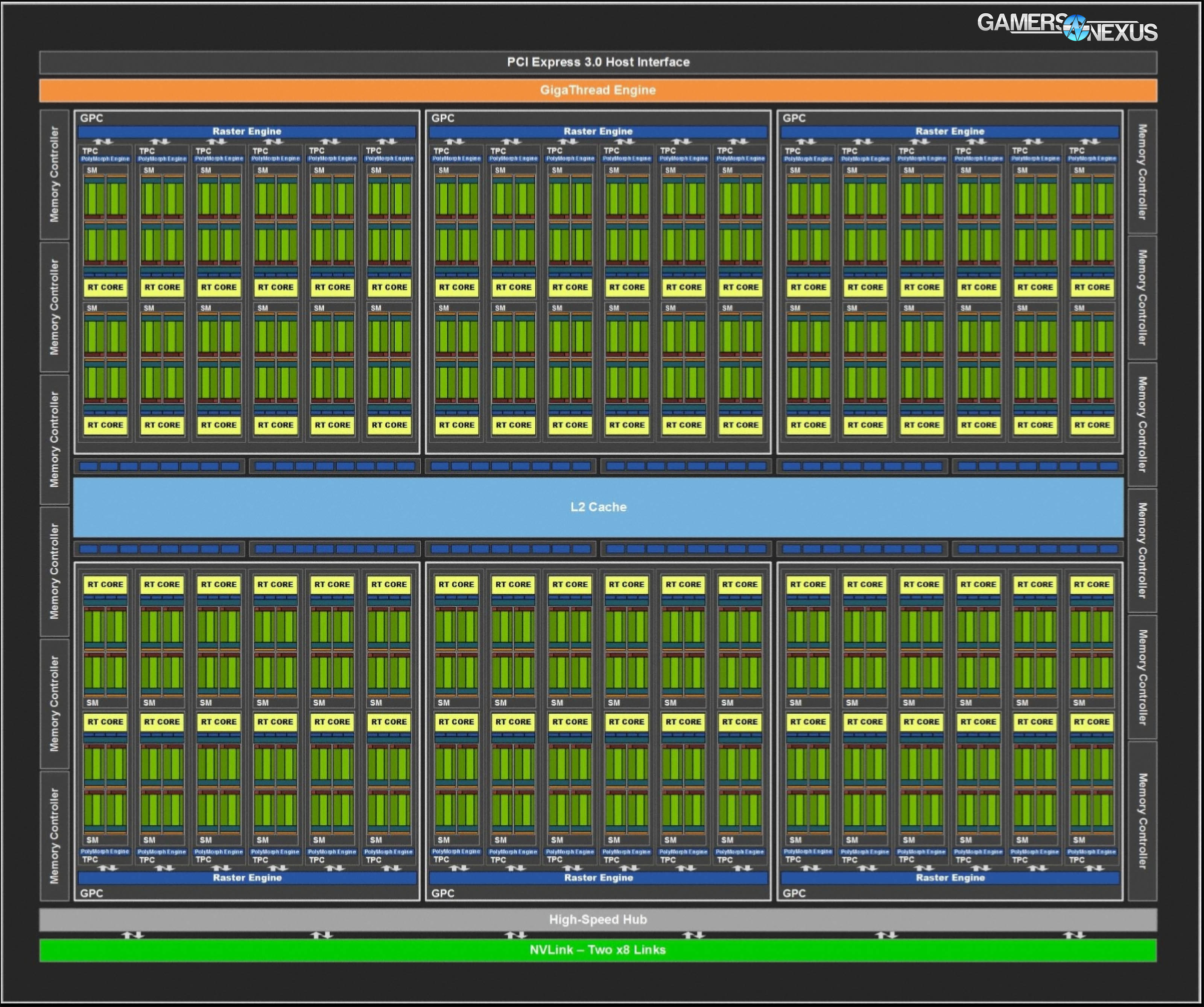
Above: The NVIDIA TU102 block diagram (RTX 2080 Ti block diagram, but with 4 more SMs)
We’ll start with a quick overview of the major changes to Turing versus Pascal, then dive deeper into each aspect. We will also be focusing on how each feature applies to gaming, ignoring some of the adjacent benefits of Turing’s updates. One of nVidia’s big things for this launch was to discuss cards in terms of “RTX-OPS,” a new metric that the company created. NVidia invented this as a means to quantify the performance of its tensor cores, as traditional TFLOPS measurements don’t look nearly as impressive when comparing the 20-series versus the 10-series. NVidia marketing recognized this and created RTX-OPS, wherein it weights traditional floating-point, integer, and tensor performance, alongside deep neural net performance, to try and illustrate where the Turing architecture will stand-out. As for how relevant it is to modern games, the answer is “not very.” There are certainly ways in which Turing improves over Pascal, and we’ll cover those, but this perceived 6x difference is not realistic to gaming workloads.
There are a lot of assumptions in the RTX-OPS formula, and most of them won’t apply to gaming workloads. In its marketing materials, nVidia claimed differences of 78 Tera RTX OPS on the 2080 Ti, or 11.3 RTX OPS on the 1080 Ti. By pure numbers, this makes it sound like the 2080 Ti is 6x faster than the 1080 Ti and is misleading, but that’s only true in nVidia’s perfect model workload. In reality, these cards won’t be anywhere close to 600% different.
Just to go through the formula, here it is:
FP32 * 80% + INT32 * 28% + RTOPS * 40% + TENSOR * 20% = 78
There are three kinds of processing going on in Turing: Shading, ray-tracing, and deep-learning. All have their own compute. NVidia tried to find a way to demonstrate its advantages in Turing over Pascal, and so created this formula to weight all of the different performance vectors. For this formula, nVidia is assuming that 20% of time goes into DNN processing and 80% goes into FP32. The company’s model also assumes that there are roughly 35 integer operations per 100 FP operations, resulting in a 35% of 80% number to equate a multiplication factor of 0.28 * INT32. After this, RTOPS is added (10TFLOPs per gigaray), and nVidia is taking 40% of that, then adding Tensor, then multiplying that by 0.2.
At first, this formula might sound like a marketing way to inflate the differences between the 2080 Ti and the 1080 Ti, and it probably is, but the math does work.
Turing Changes - Technical Overview
Anyway, let’s get into the technical details. NVIDIA is pushing architectural, hardware-side updates and software-side or algorithmic updates, but all of them relate back to Turing. The biggest changes to the core architecture are as follows:
- Integer and floating-point operations can now execute concurrently, whereas Pascal would suffer a pipeline stall when integer operations were calculated. Turing has independent datapaths for floating-point math and integer math, and one would block the other when queuing for execution. Floating point units (CUDA cores) often sit idle in Pascal, but NVIDIA is trying to reduce the idle time with great concurrency.
- A new L1 cache and unified memory subsystem will accelerate shader processing
- NVIDIA is moving away from the Pascal system of separate shared memory units and L1 units. For applications which do not use shared memory, that SRAM is wasted and doing nothing. Turing unifies the SRAM structures so that software can use one structure for all of the SRAM.
- Turing has moved to 2 SMs per TPC and has split the FPUs between them, resulting in a GPU which runs 64 FPUs per streaming multiprocessor, whereas Pascal hosted 128 FPUs per SM, but had 1 SM per TPC instead. The end result is the same amount of FPUs per TPC, but better segmentation of hardware, which benefits memory allocation. For workloads that don’t need shared memory, Turing can scale up to 64KB of L1, or can scale down to 32KB of L1 for applications that do need shared memory. L1 uses the same bus that’s built for shared memory, allowing both equally high bandwidth. Turing ends up with 6MB of L2 for its largest chip, versus 3MB of L2 on Pascal. L1 is now 64KB of shared + 32KB of load/store, or the inverse, depending on the application, with 2 L/S units for a multiplication factor of 2 on these stats. Pascal used 24K of L1 and 2 sets of 96KB shared memory instead.
- GDDR6 has 40% reduced end-to-end crosstalk and can overclock beyond the 14Gbps stock speed.
Big Turing – TU102 Specs & the RTX 2080 Ti Specs
Big Turing can be seen defined below:
TU102 Full GPU | TU102 2080 Ti GPU | |
CUDA / SM | 4608 / 72 | 4352 / 68 |
RT | 72 | 68 |
Tensor Cores | 576 | 544 |
TMUs | 288 | 272 |
Memory | 12x 32-bit GDDR6 controllers | 11x 32-bit GDDR6 controllers |
ROPs | 8 per controller | 8 per controller |
Registers | 256KB per SM | 256KB per SM |
L1 Cache | 96KB L1/shared memory per SM | 96KB L1/shared memory per SM |
L2 Cache | 512KB per controller | 512KB per controller |
INT32 Units | 4608 | 4352 |
FP32 Units | 4608 | 4352 |
FP64 Units | 144 | 136 |
Double Precision Ratio | Ratio: 1/32 | Ratio: 1/32 |
Like usual, the GPUs revealed thus far aren’t the full versions of what NVIDIA has created. The biggest GeForce Turing GPU is the TU102 GPU, presented in the Ti with 4352 FPUs across 68 SMs. In reality, the full-size Turing GPU is 72 SMs and 4608 FPUs, adding 4 SMs on top of the 2080 Ti. This indicates room for a GPU with an additional 256 FPUs – perhaps room for a Titan in the future, although not much.
TU102 wholly runs with 72 SMs. At 64 FPUs per SM, that translates to 256 more FPUs than revealed in the 2080 Ti. 8 Tensor cores per SM pushes to 576 over 544, there’s the usual TMU bump from having an additional 4 SMs with 4 TMUs each. Memory is split across 12 32-bit wide GDDR6 controllers, or 11 on the 2080 Ti, which is what gives us our ROPs calculation. For ROPs, we end up with 8 per controller, for 88 on the Ti and 96 on the biggest TU102 GPU. Cache is about 6MB on TU102, or about 5600K on the 2080 Ti. The additional memory controller would allow for an additional memory module, just like Pascal’s Titan and 1080 Ti difference.
As a side-note, FP64 is still limited to the largely useless ratio on previous GeForce cards.
Streaming Multiprocessor Changes
Getting deeper into the architecture, Turing makes several changes from the amalgamation that was last generation’s Paxwell design. We made a block diagram to help illustrate the hierarchy of containers. We’ll put that on screen below:
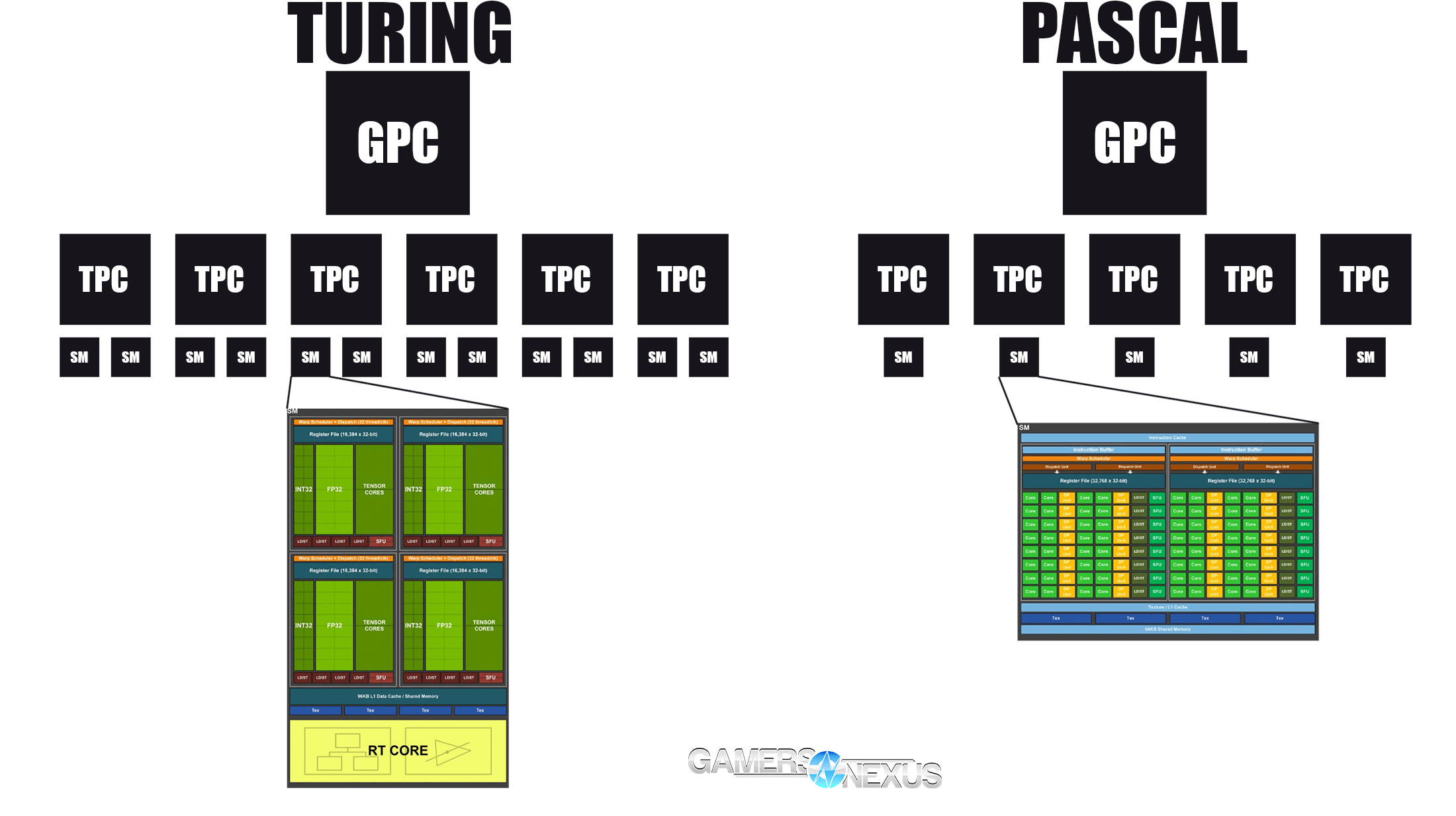
And nVidia's SM diagram:
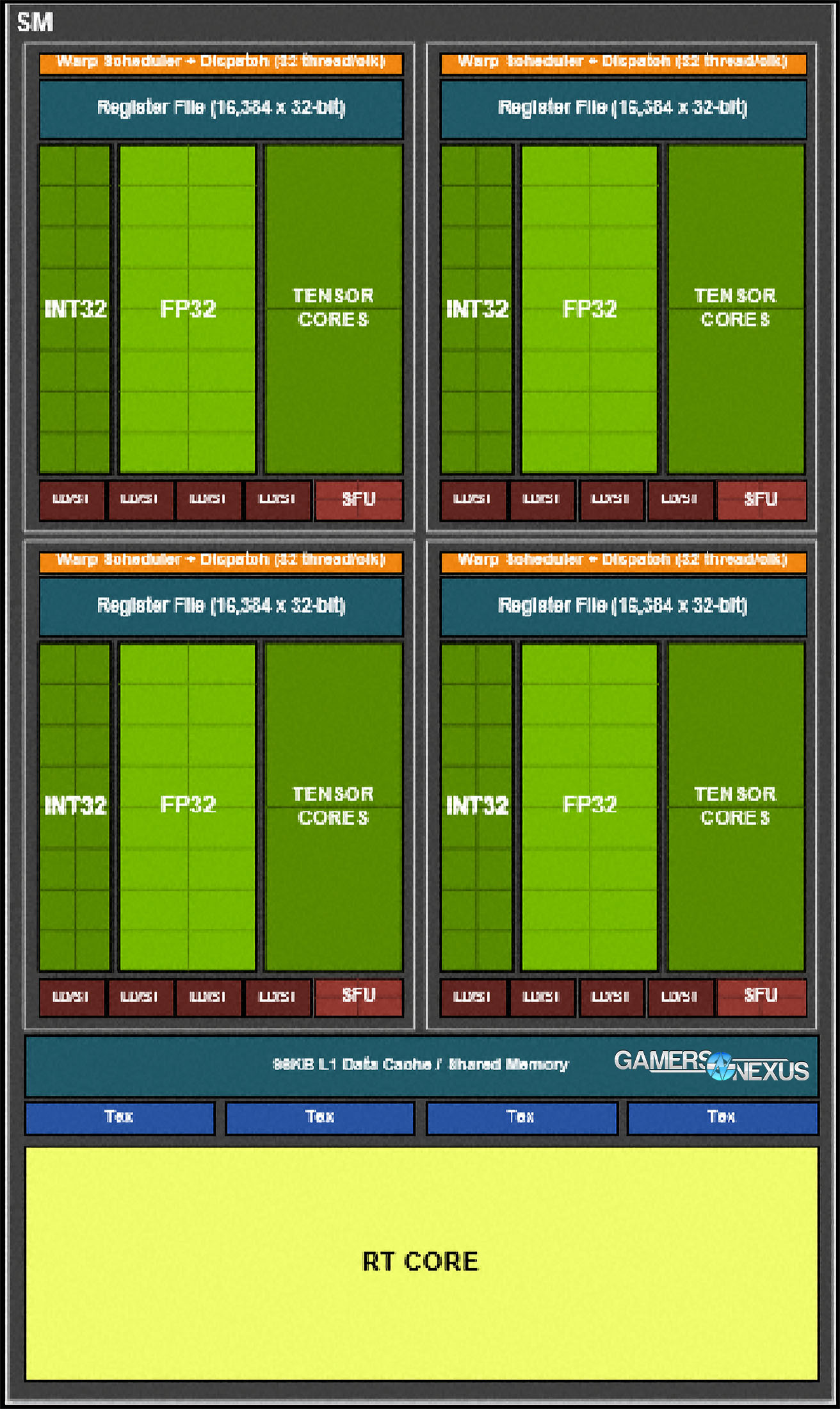
Each SM is split into four blocks, each of which contains 16 FP32 FPUs, 16 INT32 units, 2 Tensor cores, 1 warp scheduler, 1 dispatch unit, an L0 instruction cache, a 64KB register file, and a unified 96KB L1 data cache or shared memory.
Turing has an advertised 50% performance-per-core improvement over the previous generation, where the previous generation had a claimed 30% performance-per-core improvement over Maxwell.
Why GPCs, TPCs, and SMs?
We should cover why GPCs, TPCs, and SMs even exist.
The command processor manages multiple queues of things talking to the GPU via DirectX, and it needs hardware available to handle each one of those inputs. Canonically, a shader comes down the pipe and several fixed functions need to happen: Shaders get spawned that might be vertex, geometry, tessellation, and so forth. You may need to access tessellators, another fixed-function piece of hardware, in order to process these commands. The command processor communicates via PCIe to the host, manages the entire GPU chip, and has some power management functions.
The GPCs are below the Command Processor. There are six GPCs in TU102. The GPC is parent to 6 TPCs, but there is also fixed-function hardware on the GPC, including dedicated raster engines. Fixed-function hardware is typically allocated along the GPC boundaries, but the GPC is also useful for grouping TPCs. At a certain level, these are all managed together as a single unit, so for example, screen space partitioning might have 6 bins that are tapped for pixel shading and surface space division. Think of GPCs as a means to allocate and distribute the workload to the right collection of sub-resources and fixed-function hardware.
Some of those sub-resources are TPCs, which are an indication of what resources are being shared and bound together. The Turing TPC, much like the Titan V’s Volta TPC, hosts 2 streaming multiprocessors. The 2 SMs share a unified cache and memory pool within the TPC. There are resources that are TPC-specific, so when a program comes down the pipe, one TPC might make more sense than another when considering the wake and sleep states of its child SMs. With two SMs sharing a unified cache and memory pool, we wouldn’t want to shut down the cache unless both SMs are asleep, and so these function as a unit. TPCs aid in power management as well: As the GPC pushes commands to the TPCs, the TPCs will wake and sleep SMs based on the optimal load balancing for minimal power consumption. If one unit is half active, it might make more sense to wake the other SM rather than wake both SMs on a new TPC, depending on how heavy the incoming load is.
Other shared resources include rasterizers. For an example, at greater than 1 triangle per clock, you’d need a way to divide up the triangles between multiple units for processing. This is where the GPCs can leverage fixed-function hardware to process a triangle and farm-out the rest of the work to its local units.
Integer vs. Floating-Point Operations in GPUs
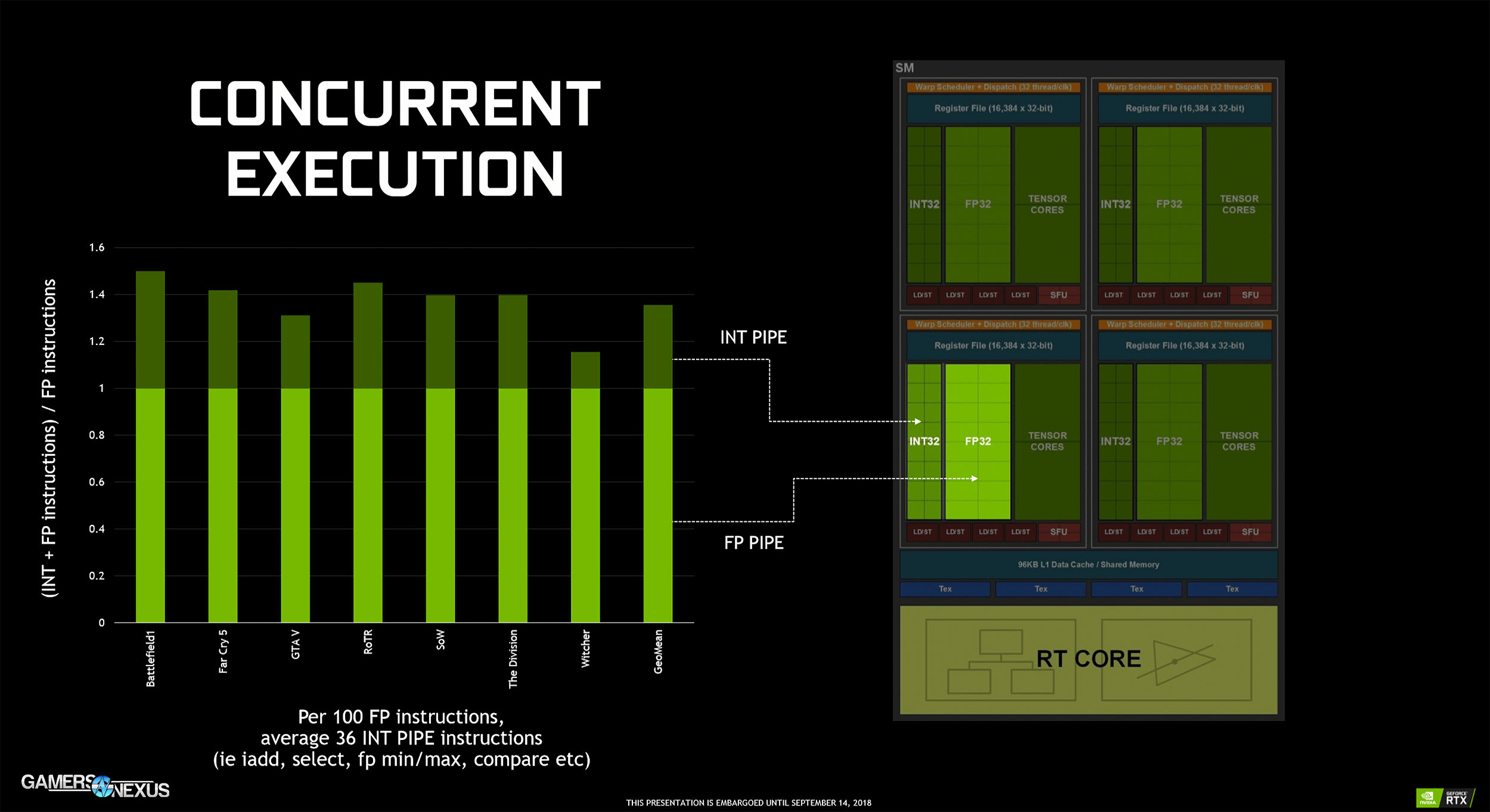
As for the SMs, the biggest change has been to concurrency of the integer and floating-point operation execution. Turing moves to concurrent execution of FP32 and INT32 operations, whereas Pascal would suffer a pipeline stall when an INT operation had to be calculated. Now, rather than stall the FPUs to allow a single INT operation to execute, they can execute simultaneously. This is allowed by independent datapaths for both the integer and floating-point units.
For examples of when Integer and Floating-Point operations would be encountered in games, we reached-out to some game engine programmers that we know. GPUs are traditionally bad at integer operations, and so INT-heavy programs typically remain on the CPU. Here’s a quote from one of our developer friends:
“Most traditional graphics operations are independent and purely FP (shading a pixel for example doesn’t require you to know about the surrounding pixels and is essentially just a bunch of dot products and multiply-adds) but ray tracing through an octree requires alternating integer and FP operations. For example, you need to find the nearest sub tree that a ray intersects to recurse into that sub tree. Intersecting with the objects is a FP operation, but deciding which is the nearest is integer and Boolean logic.
“How will this help games? If you can move more sophisticated ray tracing to the GPU, you can improve the quality of lighting algorithms there. Pixel shaders can use this ray trace data to calculate real-time shadows. Or you could move physics simulation to the GPU, freeing the game to simulate more complex game systems.”
Asking nVidia engineers of examples for when INT is used in GPUs, we were provided the following answer:
“The actual computations in a shader will typically be floating point. However, every computation is preceded by getting the data and followed by making decisions based on the data (and then in a long shader this likely repeats, ie get new data, do new compute, make new decisions etc).
“Getting the data involves address math (integer adds for example for the addresses) and making decisions often involves comparing results vs each other or vs thresholds, or taking the min/max of the floating-point results, etc. None of these instructions are floating point multiply-add operations.
“Definitely the bulk of instruction counts for shaders are still those floating point multiply-add instructions, but the other instructions are not negligible. By our measurements, for every 100 floating point multiply-add instructions there were about 36 ‘integer’ instructions in addition that would take floating point issue slots if we didn’t have a separate unit. Note that while we call the unit an “integer” unit, it actually performs both integer and simple floating point operations, like the floating point compare / min / max operations mentioned above.”
And to really bring it back for basics, integers in programming can be thought of as pure, whole numbers – no decimal – while floats will have decimal points with varying degrees of precision (FP16, FP32, FP64). An example of a float in a game might be player coordinate location or object positioning, while an example of integer might be object/enemy counting or resource counting (wood/stone/food supply). A lot of integer in games is pushed to CPUs, of course.
Turing Memory & Cache Subsystems
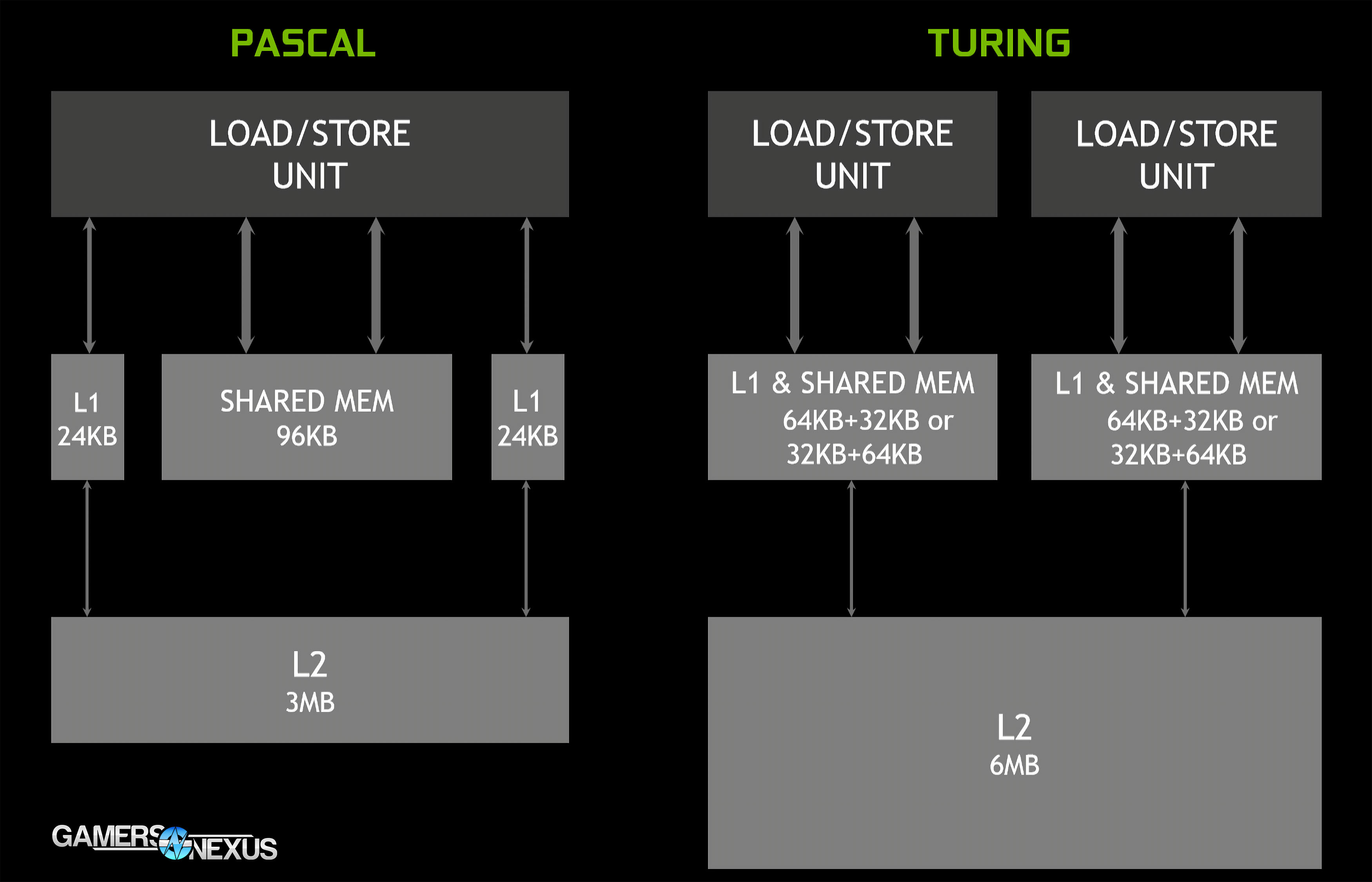
The memory and cache subsystem receive some of the most substantial updates in Turing. Memory is now unified, so there is a single memory path for texture caching and memory loads, freeing-up L1 for memory closer to the core. Applications can decide whether they need more shared memory or more L1 cache, divisible into groups of either 64K of L1 and 32K of shared or the opposite, split across 2 load/store units. This helps deal with applications where one structure may go unused, leaving expensive SRAM unutilized. Unifying the structures into one allows SRAM to be used where it is most needed, keeping processing as close to the GPU as possible.
What Are Turing Tensor & RT Cores?
Tensor cores and RT cores are also a big part of this architecture, but one which will primarily be leveraged in very targeted applications that have made explicit use of these new cores. For gaming chips, it’s more about inferencing than training, because everything is done in real-time.

As for RT cores, these are specifically used for accelerating Bounding Volume Hierarchy navigation when testing for points of intersection between rays that are traced and triangles that may collide. BVHs are used in many 3D applications, like in our own intro animation within Blender, and are useful for storing complex 3D data. Ultimately, 3D objects look something more like what’s on screen above – just a mess of numbers – and that’s what the GPU and CPU are dealing with. When a GPU is trying to determine if a ray intersects with a triangle, it must scan this entire list to determine if there’s a hit. Doing creates pipeline stalls and makes real-time ray tracing difficult, but not impossible, as it has been done as recently as 2014’s Tomorrow Children game. Still, in order to speed-up intersection checks, all of this data can be shoved into a bounding volume – this isn’t new technology either, by the way – and then the application and GPU can determine whether the ray intersects with different groupings of geometry.
With an intersection check using bounding volumes, you’re cutting an object into a few key pieces so that the ray can be checked against larger groups before getting granular. This helps eliminate triangle checks on triangles that are definitely not in the ray’s path, and continually narrows down bounding volumes until the correct group of triangles is found.
The shader uses a ray probe to find the section of triangles, then it decodes that section, intersection checks to see which sub-section the triangle might be in, and continues. Scanning like this takes thousands of cycles, so it is not at all feasible for a GPU to complete while remaining real-time. We ray-traced our GN intro, and that took weeks to do.
The RT cores accelerate this by parallelizing the workload. Some RT cores will work on BVH scans while others are running intersection checks with triangles, fetching, and triangle scanning. The SM, meanwhile, can continue normal processing of floating-point and integer operations concurrently, and is no longer bogged-down with BVH scans for rays. This allows normal shading processing to continue while the SM waits for the ray. Of course, all of this hinges upon game developers deciding to adopt and use the RTX SDK for their games, and it could take years before we start seeing any meaningful implementations beyond the first handful of titles. The technology has a sound foundation, but minimal practical applications at this time, limiting its usefulness. We’ll talk about this more in our review.
RTX SDK and Practical Applications
Let’s get into some examples of what the RTX SDK can be used for before closing-out.
A few interesting notes on RTX: First, like AMD did with True Audio, RTX could be used for sound tracing. It can also be leveraged for physics and collisions by tracing rays into objects, or for AI and NPC visual sight data. At present, we are not aware of any such implementations, but it is possible.
In gaming applications, RTX will be mixed with standard rasterization. This is not full-scene ray tracing that nVidia is enabling, it is highly selective. Thresholds are used to determine what should or shouldn’t be ray traced in a scene and, at present, nVidia is only using 1-2 samples per pixel plus denoising to make ray tracing feasible in real-time. There is a long way to go yet for the full dream to be realized. RTX is useful for 100% ray traced scenes, but mostly those in which there are pre-rendered animations – i.e. not in real-time.
Separately from this, ray tracing can be used to cull objects with greater accuracy than bounding box volumes are today, but we aren’t sure if there are any applications of this in games, and we are also unsure of if this would even work when considering how many cards don’t reasonably support accelerated ray tracing. A game developer would have to build the game with traditional bounding box culling and ray traced culling, which could complicate competitive landscapes.
Shadow reflections are also interesting use cases for ray tracing. NVidia isn’t denoising the entire image and applies one denoising filter per light, so more filtering may be necessary for filtration of the entire scene at the same time. This means that increasing light sources will decrease performance, and the population of tech demos with a single light seems to solidify this.
Denoising requires specific data on hit distance, scene depth, object normal, and light size and direction. There are three types of denoisers used in RTX: directional light denoisers, radial light denoisers, and rectangular denoisers, all of which use different algorithms to determine ground truth for the image.
Turing Architecture Conclusion
We have a lot to learn about Turing yet, but most of our next work will be based upon performance testing. We will be running several feature tests to better analyze core aspects of Turing’s computational capabilities, alongside its viability as a “normal” gaming product (e.g. for existing games). The cards are interesting and complex, and we hope that this Turing architecture deep-dive has helped provide some foundational understanding as to what nVidia is planning for this launch.
Editorial: Steve Burke
Video: Andrew Coleman