Windows 10 Hardware-Accelerated GPU Scheduling Benchmarks (Frametimes, FPS)
Posted on
Hardware-accelerated GPU scheduling is a feature new to Microsoft’s May 2020 update, Windows 10 version 2004, and has now been supported by both NVIDIA and AMD via driver updates. This feature is not to be confused with DirectX 12 Ultimate, which was delivered in the same Windows update. Hardware-accelerated GPU scheduling is supported on Pascal and Turing cards from NVIDIA, as well as AMD’s 5600 and 5700 series of cards. In today’s content, we’ll first walk through what exactly this feature does and what it’s supposed to mean, then we’ll show some performance testing for how it behaviorally affects change.
Enabling hardware-accelerated GPU scheduling requires Windows 10 2004, a supported GPU, and the latest drivers for that GPU (NVIDIA version 451.48, AMD version 20.5.1 Beta). With those requirements satisfied, a switch labelled “Hardware-accelerated GPU Scheduling” should appear in the Windows 10 “Graphics Settings” menu, off by default. Enabling the feature requires a reboot. This switch is the only visible sign of the new feature.
The best first-party source for information on the update is a post on Microsoft’s DirectX blog, which describes hardware scheduling in broad terms. The Windows Display Driver Model (WDDM) GPU scheduler is responsible for coordinating and managing multiple different applications submitting work to the GPU. This relies on “a high-priority thread running on the CPU that coordinates, prioritizes, and schedules the work submitted by various applications.” The GPU may be responsible for rendering, but the CPU bears the load of preparing and submitting commands to the GPU. Doing this one frame at a time is inefficient, so a technique called frame buffering has become common, where the CPU submits commands in batches. This increases overall performance, which could manifest as an increased framerate, but it also increases input latency. When a user hits a button, nothing will happen until the GPU gets to the next batch of submitted frames. The larger the batch, the longer the potential wait. The Microsoft blog post describes frame buffering as practically universal, but some games allow adjusting the size of the buffer or disabling it entirely.
Hardware-accelerated GPU scheduling offloads the work from that high-priority CPU thread and instead gives it to “a dedicated GPU-based scheduling processor.” The fact that cards as far back as Turing have the hardware to support this feature implies that it’s been in the works for some time now. Microsoft describes the handover as “akin to rebuilding the foundation of a house while still living in it,” in the sense that this is a huge change that will ideally be invisible to the end user. The most explicit description offered in the post is this: “Windows continues to control prioritization and decide which applications have priority among contexts. We offload high frequency tasks to the GPU scheduling processor, handling quanta management and context switching of various GPU engines.” Nowhere in the post does Microsoft directly claim that applications will run faster; instead, they go out of their way to say that users shouldn’t notice any change.
That hasn’t stopped anyone from looking for magical performance improvements, though. NVIDIA and AMD have encouraged this with vague-but-positive wording. From NVIDIA: “This new feature can potentially improve performance and reduce latency by allowing the video card to directly manage its own memory.” From AMD: “By moving scheduling responsibilities from software into hardware, this feature has the potential to improve GPU responsiveness and to allow additional innovation in GPU workload management in the future.” Both of these descriptions allude to latency, as does the Microsoft post. This opens up two areas of improvement for testing, summarized by description in the graphics menu, which reads “reduce latency and improve performance.” The first is input latency, which we can and have tested for during our coverage of Google Stadia, but we don’t think this is as big a deal as some people expect it to be. Microsoft’s blog post describes hardware-accelerated GPU scheduling as eliminating the need for frame buffering, which is a known source of input latency.
Based on that description, hardware-accelerated GPU scheduling shouldn’t reduce input latency any more than simply disabling frame buffering, which is already a built-in option in many games, and is further often an option in the GPU driver control panels. The second area of potential improvement is in the framerate of CPU-bound games, since some amount of work is offloaded from the CPU. The logical assumption is that this effect would be most noticeable on low-end CPUs that hit 100% load in games, likely more than would be the case in GPU-bound scenarios and with GPU VRAM constraints.
For testing, we started out with an i3-10100 with hyperthreading disabled to create an extreme CPU bottleneck on a modern system, and then did some verification testing with an i9-10900K. Check our testing methodology piece for CPUs in 2020 for the basics, but note these results aren’t directly comparable to other CPU benchmarks we’ve done in the past (hardware is mostly the same, though). We’re using a fresh install of a different version of Windows with different drivers, and on top of that, we’ve disabled hyperthreading on the i3. We encountered lower-than-normal 0.1% lows in all tests regardless of settings, but this isn’t anything to do with GPU scheduling and is instead a change in the methodological approach and a change in other variables within the test environment. Because this is a one-off test, we are not adhering to the exact same testing policies outlined in our CPU testing methodology documentation for 2020.
One other note: Expect to see some negative scaling in some results. We’ve discovered at least one game that has significant performance loss from enabling GPU scheduling, and NVIDIA has also posted patch notes where it has notified users of the same bug for the game Divinity: Original Sin 2. This implies to us that more of these are out there, so don’t be shocked if you see low performance with this feature in some instances. It’s still very early.
Hitman 2
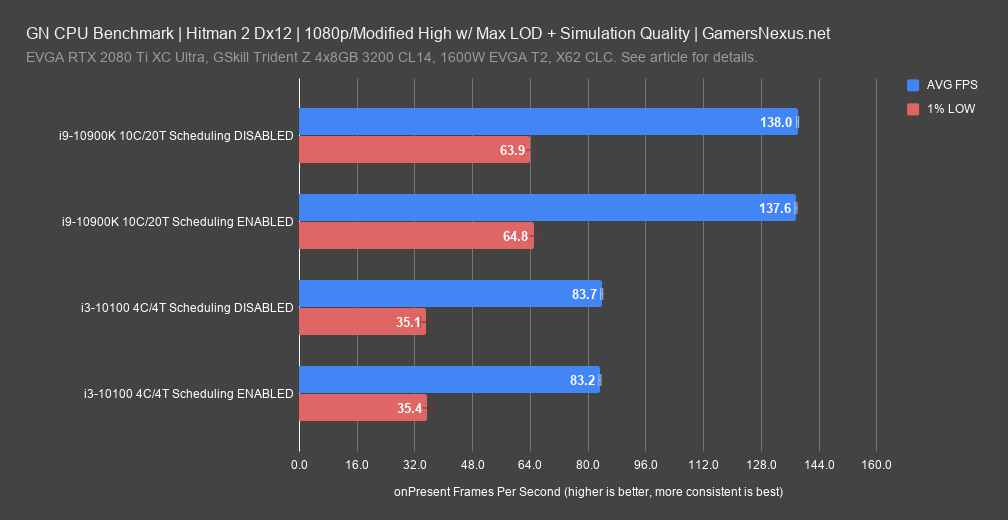
Hitman 2 showed no difference between tests. The percent scaling is actually fairly close to GTA’s (later), but with a lower overall average framerate since it’s a different game. We’re going to run out of ways to say that there just isn’t any noticeable change. This held true for both the i3-10100 with 4 threads enabled and the i9-10900K with all 20 threads enabled. AVG FPS is 138 for the GPU scheduling disabled 10900K result, or 137.6FPS AVG for the enabled result. That’s run-to-run variance. The 1% lows posted 63.9 averaged against all the repasses versus 64.8FPS 1%, so once again, that’s variance.
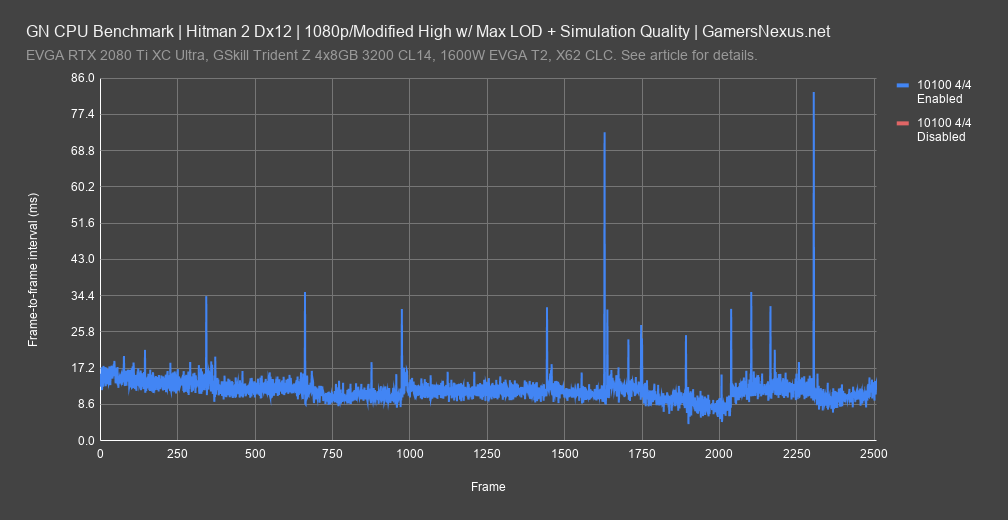
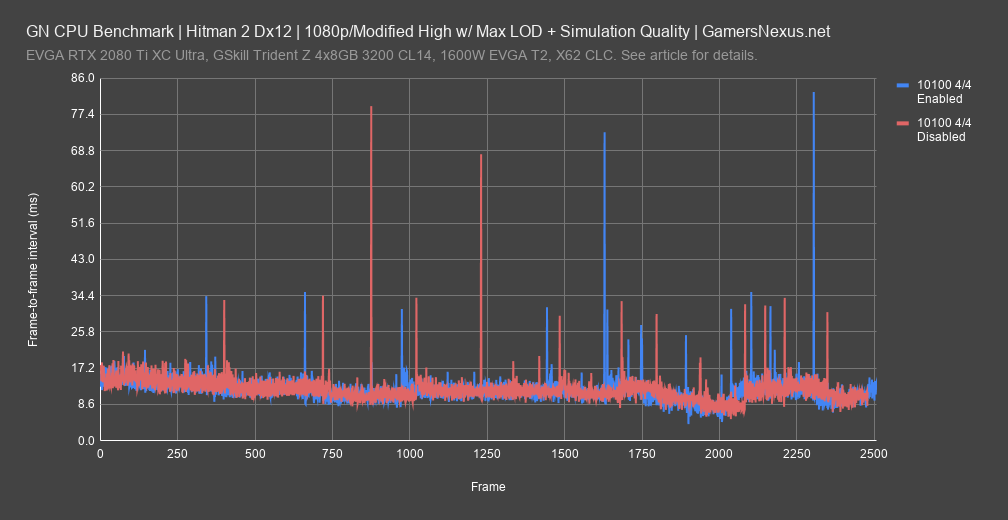
Here’s a frametime plot to show the i3-10100 with hyperthreading disabled. Frametime plots are the truest empirical representation of player experience, and show frame-by-frame rendering intervals as measured in milliseconds. We have no abstractions here, and this is the base metric of time. Remember that 4C/4T means we’ll run into a lot more frametime variability than in its stock 4C/8T configuration. If we draw one line and then the other, you’ll see that they plot almost exactly on top of each other. Just like in the abstraction from the base metric of time -- FPS -- we’re seeing that this particular dataset is nearly identical with scheduling on and off.
The 10900K produces a similar frametime plot, but this one is the more important one.
F1 2019
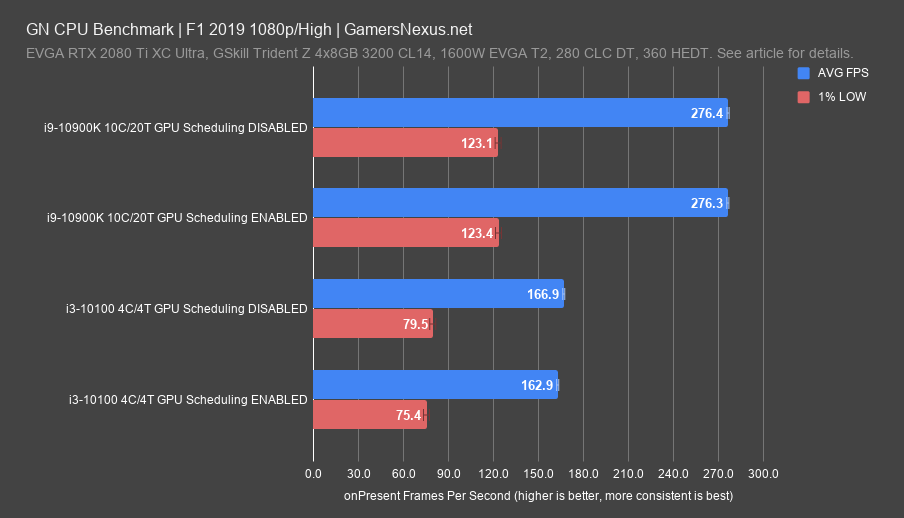
F1 2019 showed more significant scaling on the 10100 than some of the other tests, but in the wrong direction. Let’s start with the 1% lows: For the 10900K, they’re functionally equivalent: We’re seeing 123.1FPS AVG and 123.4FPS AVG 1% low. That’s within our variance run-to-run. The 10100 shows similar results: 79.5 versus 75.4, which is right at the border of testing variance for the less granular 1% lows. We have a range of about +/- 2FPS 1% low for this set of data, so that’s just at the outer bound. This is repeatable, and the enabled result is consistently lower than the disabled result for the 10100’s 1% low numbers.
For the averages, the 10900K posted results that are again functionally identical at 276.4 and 276.3FPS AVG; it’s hard to get this kind of consistency when we want it, so that’s fair to call ‘the same.’ For the 10100, the result is outside of run-to-run variance for this set of test data and is repeatable. We’re seeing a decrease of about 2.4% in AVG FPS from 167 to 163FPS at 1080p. That’s not enough to affect the game or even notice, but it is a repeatable result, at least in these early stages of the feature on our test platform. In checking some data from Tom’s Hardware’s earlier run with a different approach from ours, Tom’s also saw negative scaling in some applications, so this so far aligns with our data.
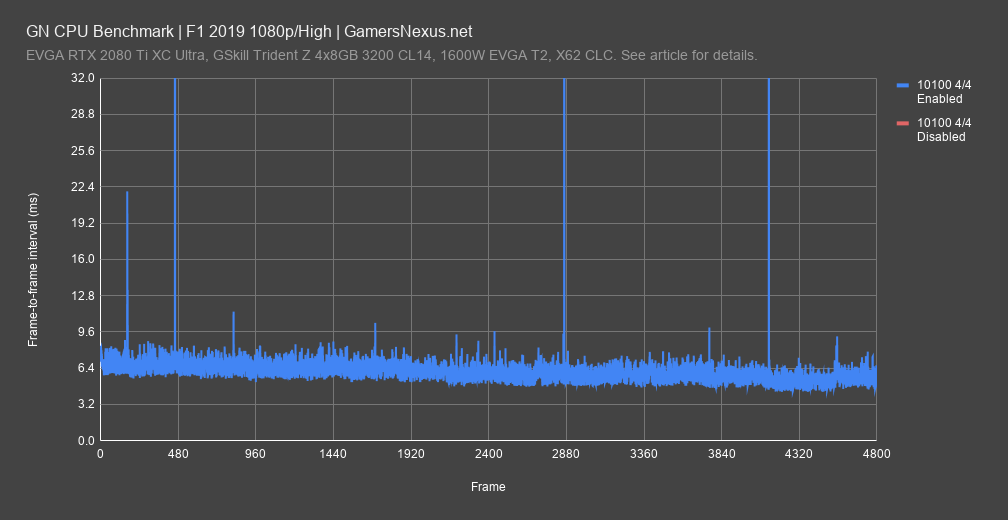
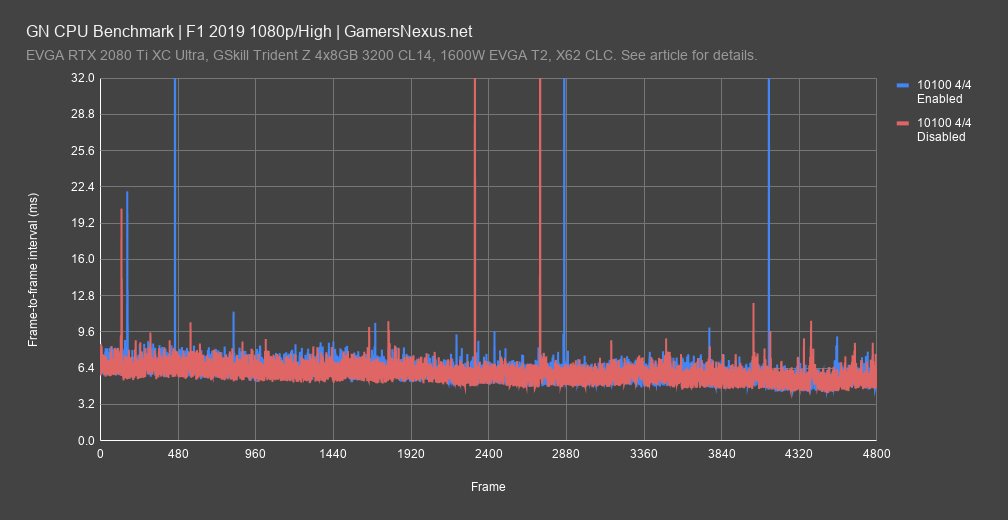
Here’s a quick frametime plot of the 10100 4C/4T configuration, first plotting the enabled result. The disabled result consistently plots under the average peaks, not the highest peaks, and so the frametime numbers align with the framerate numbers previously, but in a way which lends some more confidence to otherwise very close data. It looks like the disabled result is consistently a bit ahead of the enabled result, at least with this platform configuration and game.
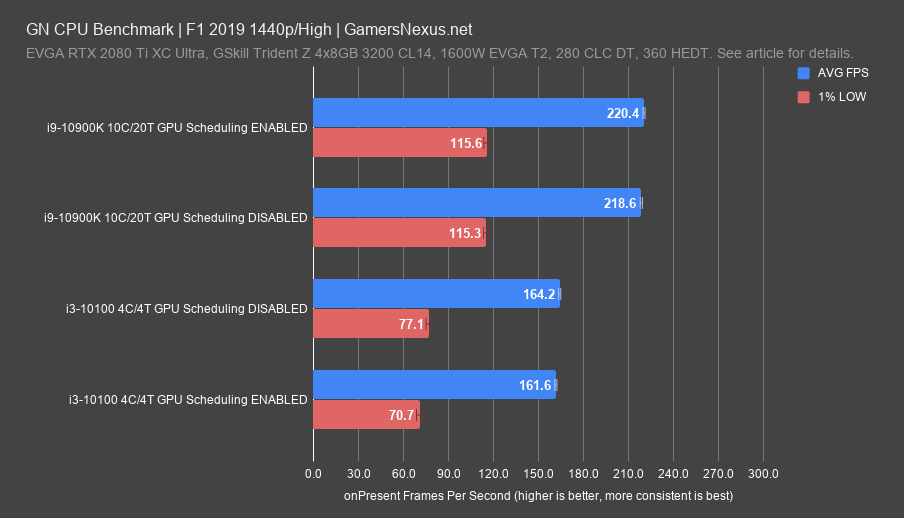
At 1440p, we saw an AVG FPS decrease of 1.6% from 164FPS AVG to 162FPS AVG. The 10900K’s average was at the border of variance for this dataset. In these early stages of the feature, and with such close-together results, it’s tough to speak with absolute confidence on the numbers -- so far, that’s what we’re seeing on our test platform. Best case, they’re about the same, and they’re so close that it’s hard to firmly call a difference. Running the 10900K for verification resulted in no change, negative or positive.
Red Dead Redemption 2 DX12
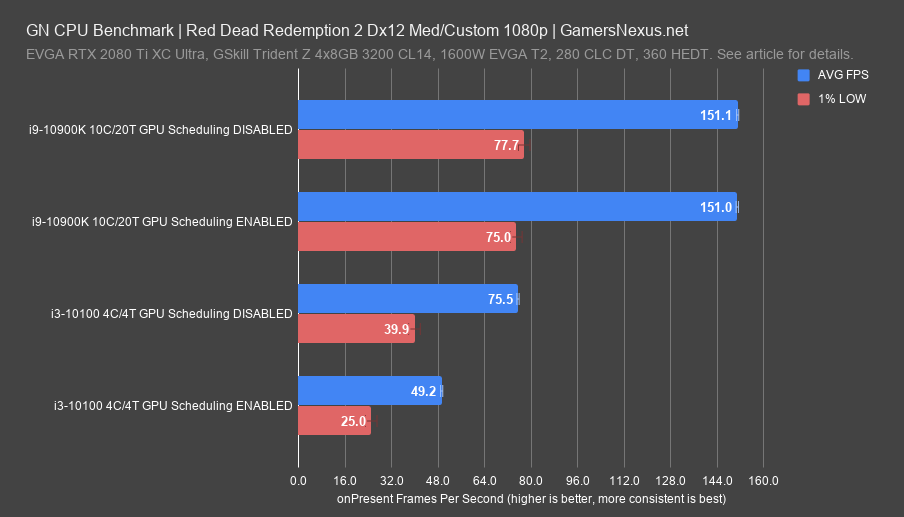
Red Dead Redemption 2 had problems with hardware-accelerated GPU scheduling with both the Vulkan and DirectX 12 APIs, but we’ll focus on DX12 for this piece. We’re aware that at least one other game has significant performance issues from NVIDIA’s driver patch notes, where they specifically name low performance in Divinity Original Sin 2 as a fixed issue. There’s not much point in discussing percentages and relative performance here--this is a bug, and presumably at some point it will be fixed, just like the previous hyperthreading debacle that we discovered in Red Dead 2. There’s a chance this bug is related, since the 10900K was unaffected. The reason we bring it up at all is that this feature is in its early days, and it’s likely there will be more games with incompatibilities that haven’t been found. We’re aware that other outlets have tested Red Dead Redemption 2 and haven’t experienced the same issue, so it doesn’t appear to be universal. Again, we’d point toward the bug we discovered at Red Dead’s launch pertaining to hyperthreading, since we’ve intentionally disabled that on the 10100; there may be some sort of link between the behavior.
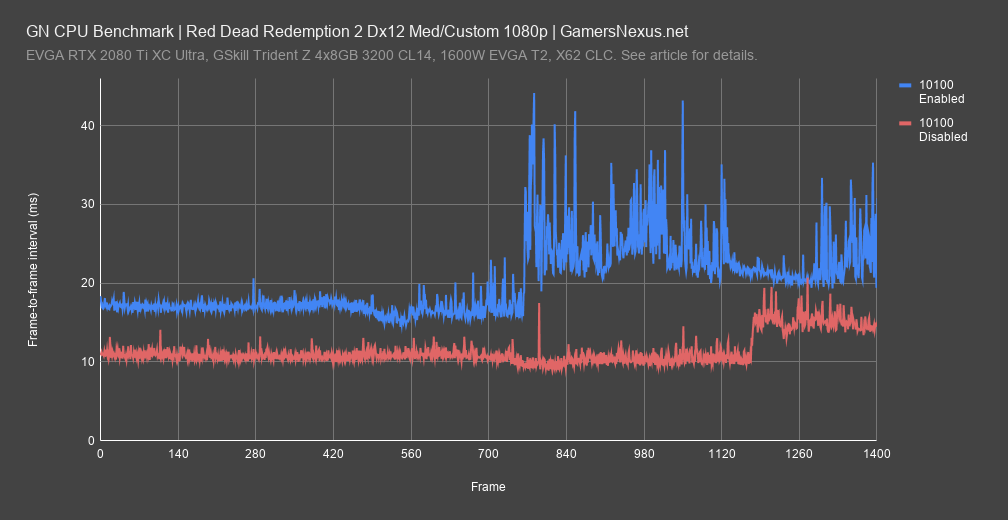
Frametimes for Red Dead show this problem. The 10100 with GPU scheduling enabled ran around 18ms at the beginning, with higher spikes later. The 10100 with GPU scheduling disabled ran at around 10-11ms, and was less spikey overall.
Grand Theft Auto V
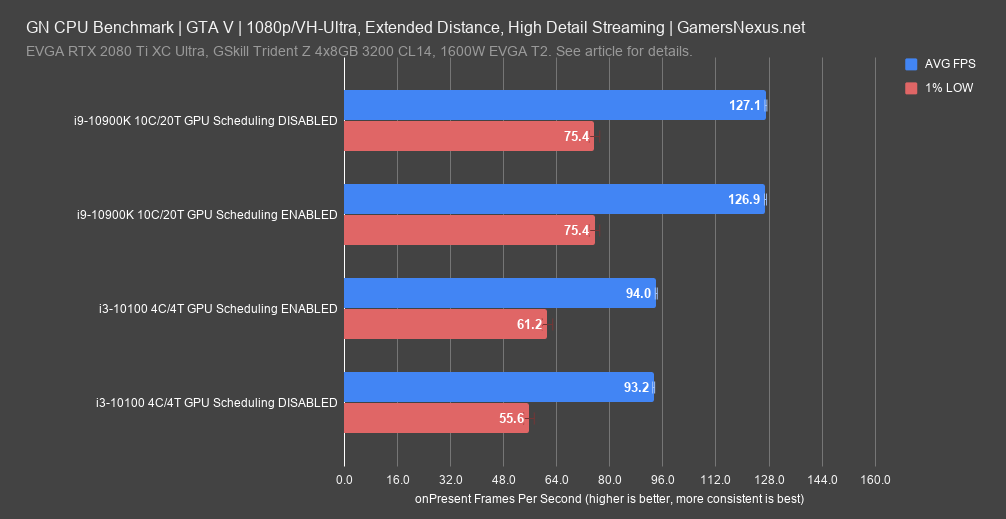
Of all the games in our test suite, Grand Theft Auto V is the best-suited to a four-core/four-thread CPU. The increase from 93 FPS to 94 FPS average is still not outside the range of random variance. We’ve seen tiny amounts of positive scaling in enough instances by now to conclude that GPU scheduling probably is helping a little bit, but on a scale that’s too small to be reliably measured. The 10900K’s results are even closer together, nearly identical both in overall averages and lows.
The Division 2
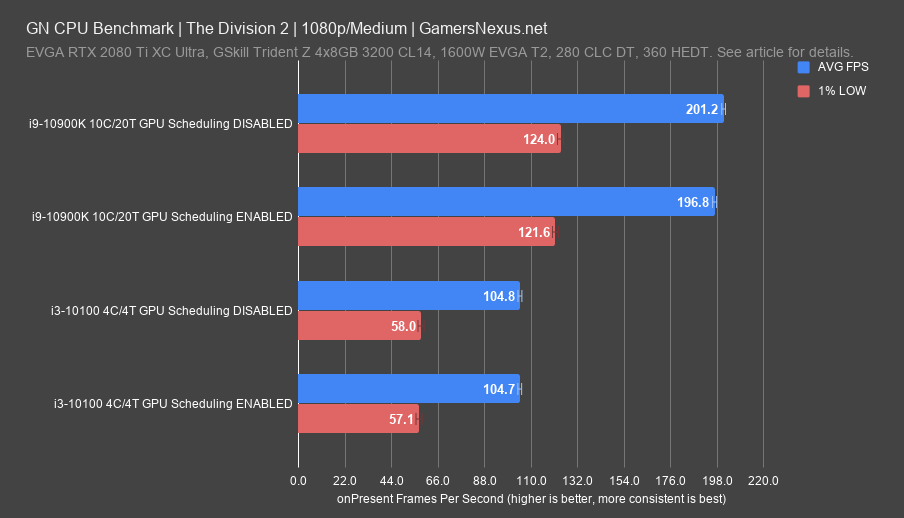
The Division 2’s results were some of the closest so far for the 10100, with near-identical averages across the board when CPU bottlenecked regardless of whether hardware accelerated GPU scheduling was used. The GPU-bottlenecked results for the 10900K had slight negative scaling, similar to the behavior TomsHardware noted in this title. The same work is being done by a different piece of hardware, so some performance difference is to be expected, positive or not.
Total War: Three Kingdoms (Battle)
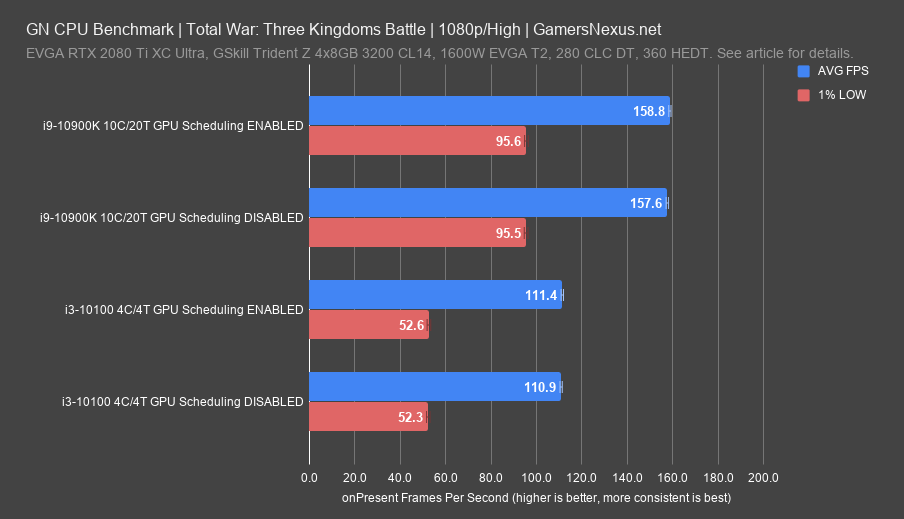
The Battle benchmark for Three Kingdoms has a similar result, with the scheduling-enabled average technically higher but by less than 1%. We can see from the 10900K’s significantly higher average framerate that the 10100 is indeed heavily bottlenecking performance, as it has in all tests so far. Part of the problem may be that even if the hypothesis about low-end CPUs benefitting from GPU scheduling is true, games rarely come anywhere close to sustaining 100% CPU load, and such instances are more likely synthetic anyway. The 10900K behaved similarly, with a technically higher FPS average when the GPU scheduling feature was enabled, but not enough to be considered significant.
Conclusions
In summary, we didn’t see significant framerate improvement nor frametime consistency uplift in any games. We haven’t seen any other outlets report huge improvements, either; even the ones that did see an uplift rarely reported more than a couple percent. Maybe if we went through our entire inventory of CPUs and GPUs, we could find a hardware combination that really benefits from hardware-accelerated GPU scheduling, but based on what we’ve seen, we’d be just as likely to find bugs. Microsoft has openly stated “[...] users should not notice any significant changes. Although the new scheduler reduces the overhead of GPU scheduling, most applications have been designed to hide scheduling costs through buffering.” The post in question was written several days after the public release of the feature, giving everyone ample time to get hyped and hunt for numbers that just aren’t there. This update isn’t designed to directly improve performance in games, it’s designed to enable unspecified future features.
Editorial, Host: Steve Burke
Editorial, Testing: Patrick Lathan
Video: Keegan Gallick, Andrew Coleman
Additional Reporting: John Tobin