RTX 2080 Ti Failure Analysis: Artifacting, Crashing, Black Screens, & Physical Defects
Posted on
The RTX 2080 Ti failures aren’t as widespread as they might have seemed from initial reddit threads, but they are absolutely real. When discussing internally whether we thought the issue of artifacting and dying RTX cards had been blown out of proportion by the internet, we had two frames of mind: On one side, the level of attention did seem disproportionate to the size of the issue, particularly as RMA rates are within the norm. Partners are still often under 1% and retailers are under 3.5%, which is standard. The other frame of mind is that, actually, nothing was blown out of proportion for people who spent $1250 and received a brick in return. For those affected buyers, the artifacting is absolutely a real issue, and it deserves real attention.
This content marks the closing of a storyline for us. We published previous videos detailing a few of the failures on our viewers’ cards (borrowed by GN on loan), including an unrelated issue of a 1350MHz lock and BSOD issue. We also tested cards in our livestream to show what the artifacting looks like, seen here. Today, we’re mostly looking at thermals, firmware, the OS, downclocking impact, and finding a conclusion of what the problem isn’t (rather than what it 100% is).
With over a dozen cards mailed in to us, we had a lot to sort through over the past week. This issue certainly exists in a very real way for those who spent $1200+ on an unusable video card, but it isn’t affecting everyone. It’s far from “widespread,” fortunately, and our present understanding is that RMA rates remain within reason for most of the industry. That said, NVIDIA’s response times to some RMA requests have been slow, from what our viewers have expressed, and replacements can take upwards of a month given supply constraints in some regions. That’s a problem.
RTX 2080 Ti Founders Edition Memory Thermals
The first update we have is on thermals. A lot of initial speculation assumed that, based on another outlet’s thermographic image taken of the backside of the PCB, the memory was overheating and therefore causing artifacting. This is rooted in the fact that artifacting is often memory related, but as we said when those images first surfaced, we had already tested memory thermals in our review. We attached thermocouples to the memory modules in the review, reproducing that chart now, and never saw any thermal issues with the memory; that said, it is always possible that some cards have thermal issues where others don’t, so we took a week to attach thermocouples all over the cards we received.
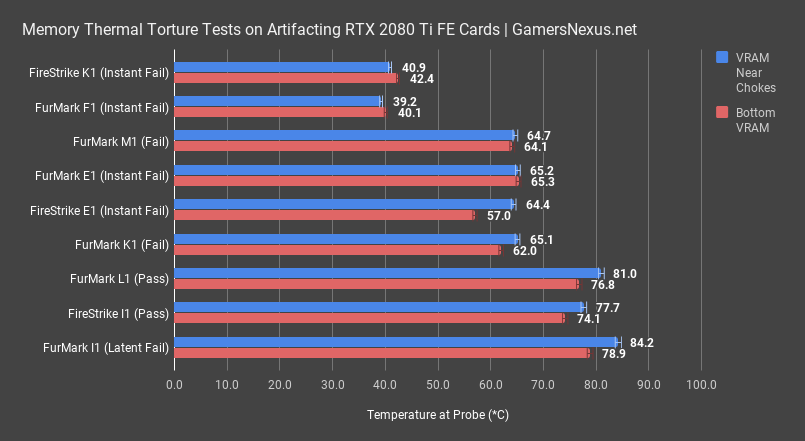
Here’s a list of FurMark and FireStrike thermal results for memory modules. We measured the two hottest memory modules – one between the GPU and capacitor bank for the VRM, and the other near the slow. We determined that these two locations are the hottest by probing each module individually, then committing to two primary modules to test.
In the worst-case scenario, card I1 failed in FurMark from the usual modes of failure – freezing, artifacting, and/or crashing – and after only about 10 minutes. This is the worst card, and had its memory measuring at 84 degrees for the module near the chokes, or 79 degrees for the module near the PCIE slot. We could not find a card worse than this one for thermals. The spec calls for temperature to be under about 95 degrees Celsius. We’re measuring the external package temperature here, so it is possible that the internal die is at its maximum thermal value, but we can’t be sure. Realistically, from experience, the delta is likely closer to 5 degrees, so it should be within spec. Even still, we wanted to see what would happen if we used one of our known-good review samples and tortured it without any heatsink or airflow on the memory. Theoretically, if hitting some magical maximum temperature triggers an instant freeze or artifacting fit, then our card without any heatsink should encounter that at the same temperature.
GDDR6 Memory Torture at 100 Degrees Celsius | 2080 Ti FE Overheating Test

This next move is inadvisable. If you remember our Hybrid card – and we’ll show some shots of it – the only way it really worked well was to add a fan or two to blast the PCB. Our CLC only covered the GPU. We re-deployed the Hybrid without any cooling on the memory whatsoever, finding that it’ll continually ramp until you feel uncomfortable. We ended up halting the test right at around 100 degrees on the thermocouple for the hottest module, which is probably about 105-110 internally. This isn’t good for the card, obviously, but the point was to see if a known-good card could be made to instantly start artifacting or crashing as a result only of high temperatures. That’s what a lot of internet conjecture suggested, so this testing looked at that. This card fared well, and still works to its full overclock potential today. Now, again, the test isn’t good for the components, but it didn’t artifact, flicker, freeze, or crash. We stopped the test. There does not appear to be a thermal shutdown that triggers from high memory temperatures.
Back to VRAM Thermals
Back to the previous chart momentarily, other memory modules ended up at 65 degrees for card E1, which failed nearly instantly. It did not even have time for any components to exceed thermal spec and overheat – E1 crashed too fast. This is not a thermal issue.
Card F1 couldn’t even finish loading the application, and so was never under any meaningful load to push the thermals.
Card I1 with FireStrike pushed 78 degrees and 74 degrees on the memory, which is within spec. Card E1 with FireStrike failed nearly instantly, and so never had a chance to get hot – it was at around 64 and 57 degrees for the modules.
You get the idea. It looks like memory thermals are not the cause of the failures for these cards. Even in I1 with FurMark, where thermals were high enough to be concerning, we know that memory thermals were not the issue. We know because the card still failed even when putting a water block on it.
Choke / VRM Thermals
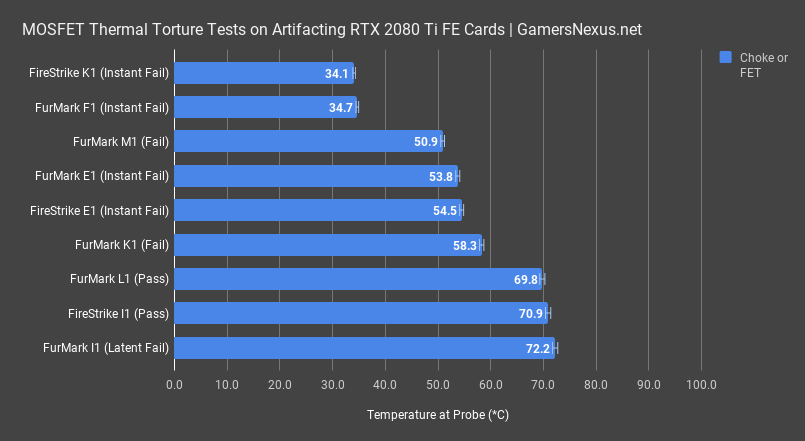
Continuing the thermal trend, we took turns measuring inductors and MOSFETs on the same cards. MOSFETs and inductors can take 125 to 150 degrees Celsius, depending on which component it is and if it has any thermal fail-safes included. Card I1 was again the hottest, at about 72 degrees for the hottest MOSFET while running FurMark. F1 didn’t run long enough to heat up meaningfully, so we can count that as another tick against thermals being the cause of issues. Card E1 in FurMark also failed quickly, never exceeding 54 degrees on its MOSFET. I1 remained hot in FireStrike, at 71 degrees for the MOSFET. None of these temperatures are hot. Even the 73-degree value is way within spec. There are no thermal issues here.
Backside Thermals

A lot of people also said that their backplates were running hot. We’ll note that this is what backplates are supposed to do, since they’re heatsinks and that means they’re working, but the Founders Edition backplate does run a bit hotter than most might be used to. Sticking a thermocouple to the backside of the hot memory module near the PCIE slot, we measured a maximum backside PCB temperature of 75 degrees on I1 in FurMark. This is within spec and not unreasonable, seeing as a PCB is just a giant conductor with shared powerplanes running through it. A significant portion of a PCB is copper, so it is going to be hot on the backside, since some heat from the memory is sinked through the PCB.
GPU & Ambient Thermals

Lest there be any concern of testing conditions, here are the ambient thermals during each test, logged second-to-second for the entire test run. We stayed within a range of roughly 22 to 23.5 degrees.
GPU thermals are also plotted here. Again, for devices that failed nearly instantly, those never got hot. They didn’t reach a steady state load and were just beginning to ramp-up. For the rest, I1 was at 76 degrees, E1 was about 71 degrees, and others were nearby. Although the FE heatsink is not impressive, there’s really no red flag with these thermals.
RTX 2080 Ti FE Firmware
We can somewhat confidently say that thermals were not the issue with these cards. The next point of consideration is firmware, as newer units are shipping with firmware revision 90.02.17.00.04, and original cards shipped with 90.02.0B.00.0E. We tried flashing a few cards to newer revisions of firmware, ultimately finding the same artifacting results that we saw previously. You can see some of those on the screen now. Firmware updates did not resolve the issue on the cards in our lab.
Windows vs. Linux – RTX 2080 Ti Artifacting, Freezes, & Black Screens

Following several requests during our livestream of the dying 2080 Ti cards, we also decided to test behavior in Windows versus Linux. We installed Ubuntu 18.04 and Unigine Heaven, then tested two cards that artifact in Windows against Ubuntu. We tested with driver revision 410 and 415. In both instances and on both cards, totaling four tests, we saw artifacting as early as the terminal. We also encountered freezes during the Heaven benchmark run, often within the same time period as the Windows tests would freeze in TimeSpy Extreme. From our testing, this issue is not isolated to Windows. At this point, we can start assuming it is almost certainly a physical, board-level defect.
Frequency Tuning

The next step was to tune frequencies to try and mitigate the artifacting and freezing behavior of the cards. We hosted a multi-hour livestream that included some frequency tuning to try and mitigate these crashes. Most devices seemed to degrade over time, but we noticed that a few benefited from clock reductions of various sorts. That said, most units we ended up with, by the time we got them, did not exhibit increased stability from intentional frequency throttling. We tried all combinations and permutations we could think of: Downclocking memory, downclocking core, downclocking both, negative power offset, positive power offset, mixing them with downclocks, 100% fan speeds and no other changes, power offsets in either direction and no other changes, and so on.
Ultimately, although a few of the users who sent their cards noted these steps could improve stability temporarily, we were not able to reproduce this in any widespread fashion.
Examples of steps taken:
Card E1
- Downclock memory – freeze by 60 seconds
- Downclock core - freeze by 60 seconds
- PWR Target 85% - freeze by 60 seconds
- Downclock mem + core to -1000/-1000 - freeze by 60 seconds
- Configure 123% PWR, lowest CLK/MEM, and +100% fan - freeze by 30 seconds
- +100% fans, no power offset – shutdown after 3 minutes
- +123% power on desktop - no crash/freeze (works fine)
- +100% fan on desktop - no crash/freeze
- +100% fans in TSE - freeze, then recover, then freeze
Board-Level Comparison
Just for good measure, we also took apart several cards and did a cursory board-level inspection. We were only really looking for anything extremely out of place, like missing thermal pads, poor contact, burned or damage components, and so on. There was only one device that demonstrated any physical defect, but it was unrelated to the issue of artifacting and is something we may discuss later. The thermal pad contact on all of the cards looks fine – we can see indentations and clear contact being made to the pads – and there are no obviously damage components. Any defect is going to be something we don’t have the tools or knowledge to see, as it’s likely in the board or in the silicon.
What we’ve done today is primarily rule things out – or mostly out, as we can’t speak with 100% certainty – like thermals, firmware, and Windows. We’ve also determined that blue screens were a separate issue, caused by early driver compatibility problems with many GSync monitors. Visible defects on the boards were not present, although we have no means of inspecting the internals of the board or the silicon.
Ubuntu Linux also exhibits artifacting issues (410 and 415), as does the newest firmware revision on the bad cards, and artifacting still occurs even when a water block is on the cards. We have to assume that thermals are not the issue on the cards we had. The biggest take away is that there’s not some magical “TjMax” trip-point whereupon artifacting kicks in. Even running our known-good review sample at 100+ degrees on the memory – decidedly a bad thing for the memory’s health – we still did not encounter a hard shutdown, thermal fail-safe, or artifacting. For anyone who thought artifacting was triggered upon hitting a certain threshold, it would appear that this isn’t the case. Sticking thermocouples on the cards also did not produce offensively high thermal numbers, although I1 was getting bad.
Speaking with some engineers in the industry, we’re left with an assumption that this is either a board-level assembly issue or an in-silicon issue. NVIDIA has noted that it is replacing any affected cards, so there’s that. The company described these units as “test escapes” and seems to think that the problem is fixed going forward. We have exceedingly high confidence that this is a hardware-level issue, but it does not appear to be an epidemic.
Editorial, Testing: Steve Burke
Video: Andrew Coleman