The Order of 10 puzzle preempted a forthcoming event that we'll be covering, publicly disclosed as occurring on May 6 at 9PM EST. Although nVidia has not technically, officially laid claim to the “#OrderOf10” puzzle, the countdown timer happens to expire precisely when nVidia's yet-undetailed Twitch.tv streaming event will kick-off. UPDATE: View our GTX 1080 & GTX 1070 coverage here.
And that full day of decoding mysteries led us to brush-up on nVidia's “Pascal” architecture, revealed years ago and announced at this year's GTC as hitting volume production. The first Pascal chip publicly known to enter production is the GP100, found on the Tesla P100 scientific and computational accelerator card. GP100 is the “Big GPU” for this generation of nVidia devices, measuring in at an intimidating 610mm^2 die size, and stands as the trailhead for imminent derivatives of the GPU architecture. Those derivatives will invariably include gaming-targeted devices – something for which the P100 is not remotely targeted – in the GeForce GTX lineup.
This article dives deep into NVIDIA's new Pascal architecture. We'll talk streaming multiprocessor layout, memory subsystems and HBM1 vs. HBM2, L1 & L2 Cache, unified memory, GDMA, and more.
As for the live-streamed event tonight, we're hoping that it'll offer us some official names for the rumored “GTX 1000” series (e.g. GTX 1080, GTX 1070, GTX 1060 Ti), but we really don't know for certain what's being unveiled. We will be covering that event tonight in full detail, whatever it may involve. Be sure to check the site and YouTube channel for updates as they're released live.
Pascal GP100 vs. K40, M40, GM200
| Tesla GPUs | Tesla K40 | Tesla M40 | Tesla P100 |
| GPU | Kepler GK110 | Maxwell GM200 | Pascal GP100 |
| SMs | 15 | 24 | 56 |
| TPCs | 15 | 24 | 28 |
| FP32 CUDA Cores / SM | 192 | 128 | 64 |
| FP32 CUDA Cores / GPU | 2880 | 3072 | 3584 |
| FP64 CUDA Cores / SM | 64 | 4 | 32 |
| FP64 CUDA Cores / GPU | 960 | 96 | 1792 |
| Base Clock | 745MHz | 948MHz | 1328MHz |
| GPU Boost Clock | 810/875MHz | 1114MHz | 1480MHz |
| Peak FP32 TFLOPs | 5.04 | 6.8 | 10.6 |
| Peak FP64 TFLOPs | 1.68 | 2.1 | 5.3 |
| Texture Units | 240 | 192 | 224 |
| Memory Interface | 384-bit GDDR5 | 384-bit GDDR5 | 4096-bit HBM2 |
| Memory Size | Up to 12GB | Up to 24GB | 16GB |
| L2 Cache | 1536KB | 3072KB | 4096KB |
| Register File Size / SM | 256KB | 256KB | 256KB |
| Register File Size / GPU | 3840KB | 6144KB | 14336KB |
| TDP | 235W | 250W | 300W |
| Transistor Count | 7.1B | 8B | 15.3B |
| GPU Die Size | 551mm^2 | 601mm^2 | 610mm^2 |
| Manufacturing Process | 28nm | 28nm | 16nm FinFET |
NVIDIA Full Pascal GP100 Block Diagram
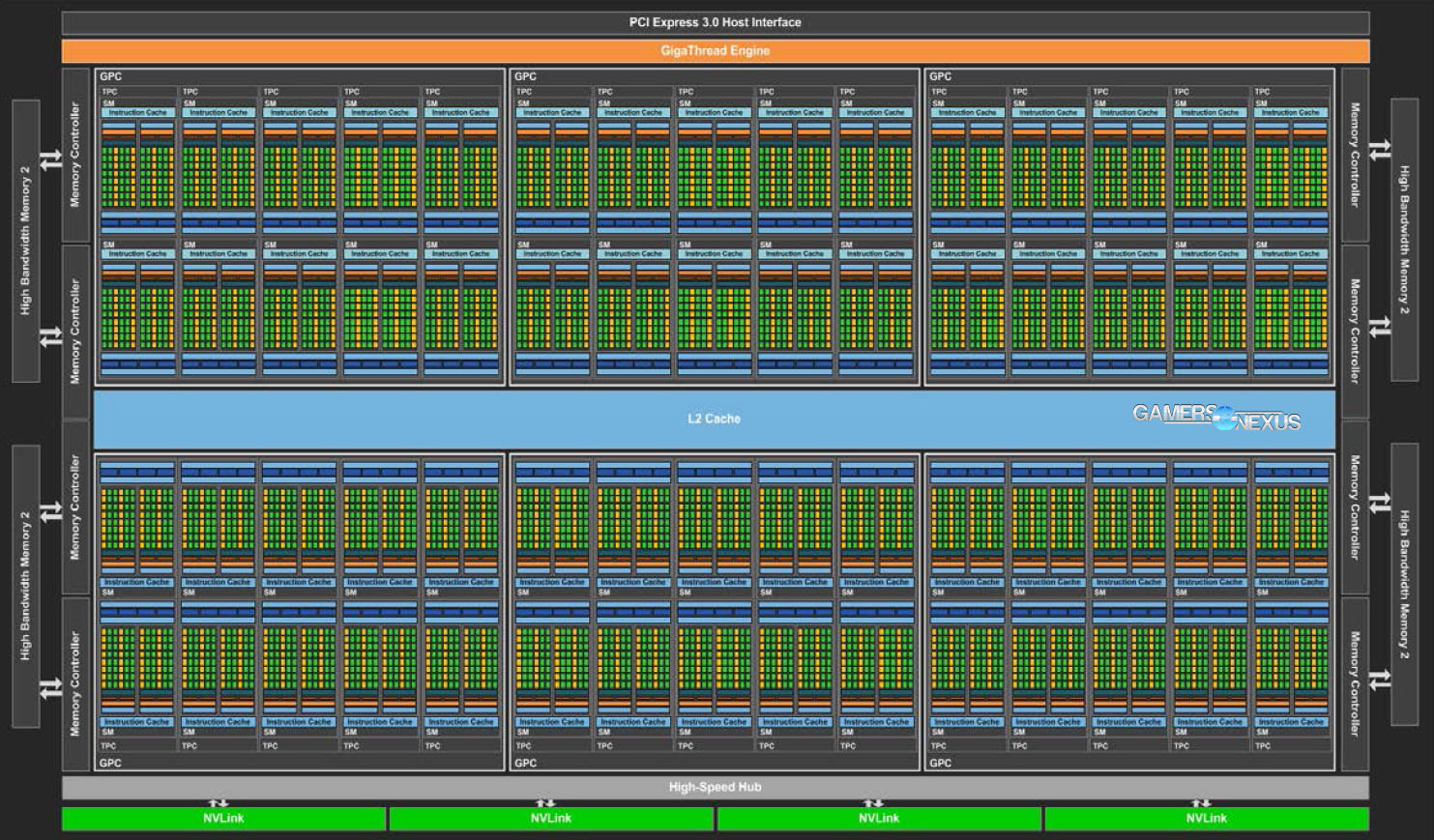
This is the architectural block diagram for the GP100 Pascal chip that was revealed at GTC last month.
GP100 is the largest GPU that nVidia has ever built, and is fabricated by TSMC on a 16nm FinFET process node. That's a major shift from the preceding 28nm process node of currently active gaming architectures from both nVidia and AMD, and it champions an era of reduced wattage and more packed-in transistors. Both items work to better the performance-per-watt “ratio,” a change nVidia began making post-Fermi and that AMD executed with Fiji. The die shrink isn't alone in performance and power consumption improvements, either; a move to FinFET transistors means that power leakage becomes less significant, and marks the EOL for planar FETs in GPUs as all major silicon manufacturers have now transitioned.
FinFET transistors use a three-dimensional design which extrudes a fin to form the drain and source, with the gate encircling the transistor's fins. GP100 has a transistor count of 15.3 billion across its 610mm^2 GPU die size. It's rated for a 300W TDP and offers a staggering 5.3 TFLOPS of FP64 (double-precision) COMPUTE performance and 10.6 TFLOPS of FP32. FP16 is also available natively (21.2 TFLOPS) on GP100 and is more critical than it might sound on paper, something we'll discuss more momentarily.

The Tesla P100 Pascal science-targeted accelerator card (not quite a “graphics card”) hosts a total of 3584 CUDA Cores capable of single-precision FP32 and 1792 CUDA Cores capable of FP64 DP COMPUTE. The full GP100 GPU would host 1920 FP64 cores. The clockrate is natively high, pushing a frequency of 1328MHz base and 1480MHz boosted (stock), and bandwidth is further aided by the new move to HBM2 memory – an absurd speed increase over GDDR5.
Let's start with the graphics processing clusters and streaming multiprocessor (SM) architecture, then get into memory.
Pascal Streaming Multiprocessor (SM) Architecture
Although variants will exist, the GP100 chip we're looking at today (Tesla P100 GPU) is modeled in the above diagram. This chip hosts six Graphics Processing Clusters (GPCs), each of which contains a set of Texture Processing Clusters (TPCs). For every one TPC in Pascal, there are two Streaming Multiprocessors (SMs); in total, there are 60 SMs on GP100, with the Tesla P100 Accelerator hosting 56. This is what an SM looks like in the Pascal architecture:
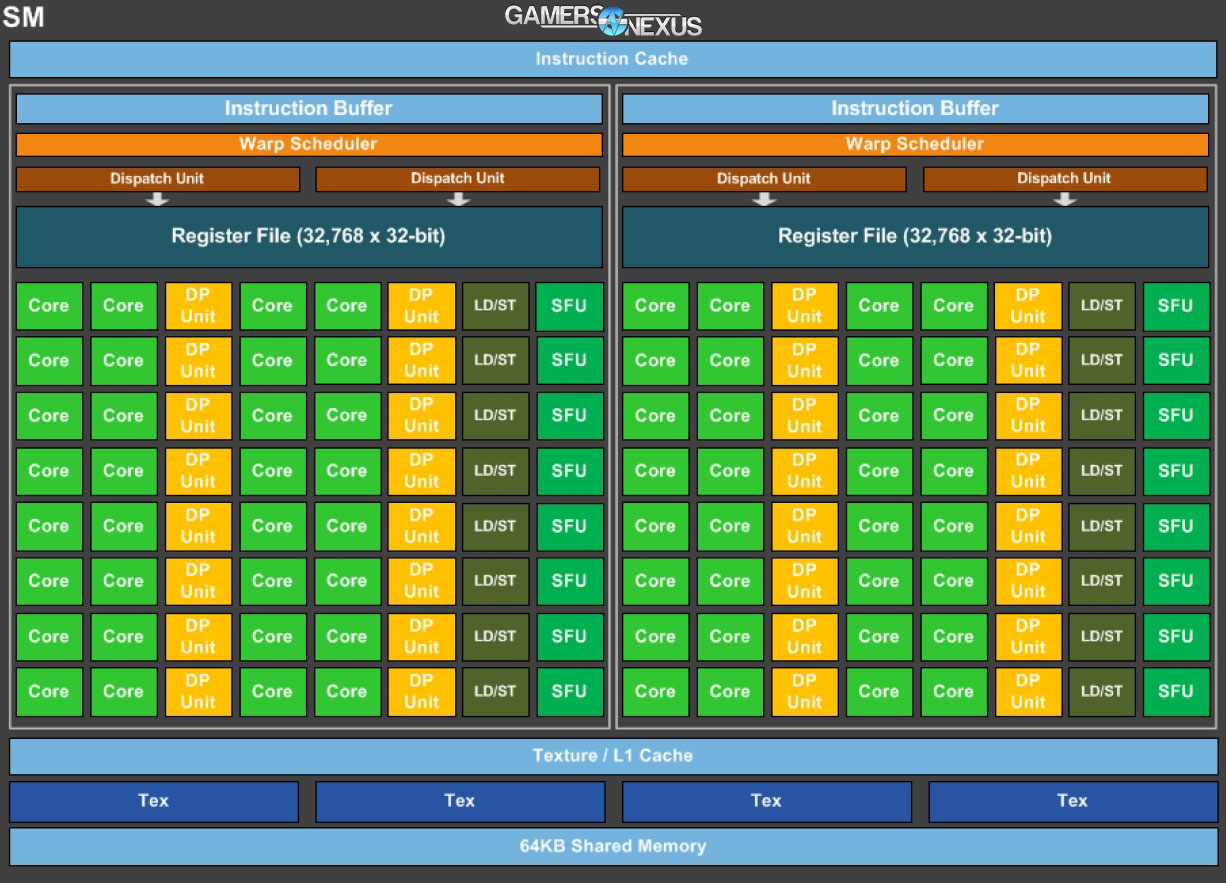
The above SM sample is reproduced ten times per GPC, accompanied by one half that count of TPCs (five per GPC). Each SM contains 64 FP32 single-precision CUDA cores and 32 FP64 cores (half) on a fully-enabled GP100 GPU; this may interest astute readers as being a reduction in total core count per SM versus previous architectures, despite an overall higher per-GPU core count. Maxwell, for instance, ran 128 FP32 CUDA cores per SM, and predecessor Kepler ran 192 FP32 SP CUDA cores per SM. The reduced CUDA core count per SM is because GP100 has been segmented into two sets of 32-core processing blocks, each containing independent instruction buffers, warp schedulers, and dispatch units. There is one warp scheduler and one instruction buffer per 32-core partition. Each partition also contains two, independent dispatch units per (four total per SM), and each partition further contains a 32,768 x 32-bit register file. The SM segments share a single instruction cache, unified texture / L1 Cache, four texture units (TMUs), and one 64KB shared memory block.
Here is the COMPUTE potential of various architectures:
| GPU | Kepler GK110 | Maxwell GM200 | Pascal GP100 |
| Compute Capability | 3.5 | 5.2 | 6.0 |
| Threads / Warp | 32 | 32 | 32 |
| Max Warps / Multiprocessor | 64 | 64 | 64 |
| Max Threads / Multiprocessor | 2048 | 2048 | 2048 |
| Max Thread Blocks / Multiprocessor | 16 | 32 | 32 |
| Max 32-bit Registers / SM | 65536 | 65536 | 65536 |
| Max Registers / Block | 65536 | 32768 | 65536 |
| Max Registers / Thread | 255 | 255 | 255 |
| Max Thread Block Size | 1024 | 1024 | 1024 |
| Shared Memory Size / SM | 16KB / 32KB / 48KB | 96KB | 64KB |
(From GP100 white paper.)
So, even though Pascal has half the cores-per-SM as Maxwell, it's got the same register size and comparable warp and thread count elements; the elements comprising the GPU are more independent in this regard, and better able to divvy workloads efficiently. GP100 is therefore capable of sustaining more active (“in-flight”) threads, warps, and blocks, partially resultant of its increased register access presented to the threads.
The new architecture yields an overall greater core count (by nature of hosting more SMs) and also manages to increase its processing efficiency by changing the datapath configuration. The move to FinFET also greatly increases per-core performance-per-watt, a change consistent with previous fabrication changes.
Because the cores-per-SM have been halved and total SM count has increased (to 10, in this instance), the per-SM memory registers and warps improve efficiency of code execution. This gain in execution efficiency is also supported by increased aggregate shared memory bandwidth (an effective doubling) because the per-SM shared memory access increases.
Pascal's datapath structure requires less power for data transfer management. Pascal schedules tasks with greater efficiency (and less die space consumed by datapath organization) than Maxwell by dispatching two warp instructions per clock, with one warp scheduled per block (or “partition,” as above).
With four texture units per SM, Pascal GP100 is outfitted with a total of 240 TMUs. A split L1/Texture cache is made available to the SM, explained in the next section.
As for why FP16 matters, it's mostly deep learning. This will only be given cursory coverage as it exits the scope of our gaming-tech website. The native FP16 support and high performance (>21TFLOPS) COMPUTE aids in applications which do not require the accuracy tolerances of double-precision. NVidia explains in official documentation that “deep neural network architectures have a natural resilience to errors due to the backpropagation algorithm used in their training.” FP16 becomes preferable in deep learning use cases, as it requires significantly less memory usage, reduces data transfer, and can improve performance ~2x over FP32.
Continue to Page 2 for L1 & L2 Cache, Unified Memory, & HBM2 vs. HBM.
Pascal Cache – L1 & L2 Cache, Unified Memory
Unified Memory and memory sharing are driving features of modernized GPU architectures. This extends beyond system resources and reaches into L1/L2 Cache and texture cache with GP100. With regard to Pascal specifically, L2 Cache is unified into a 4096KB pool (as opposed to GM200's 3072KB L2 Cache) that further reduces reliance upon DRAM and power draw, thereby garnering additional performance gains.
Pascal dedicates a single pool of 64KB of shared memory to each SM, eliminating previous reliance on splitting memory utilization between L1 and shared pools. GP100 uses Unified Memory in conjunction with NVLink (for scientific computation applications) to improve concurrent read-modify-write parallelism within atomic memory operations.
Unified Memory reduces programmer effort by streamlining application development with the provision of a unified virtual address space that “houses” both system RAM and GPU VRAM. Programmers can write less manually-intensive code and focus on improving parallelism, thanks in part to a reduction in explicit memory copy calls to move memory between system and local GPU memory. This single pool of memory is accessible by both the CPU and GPU in relevant applications and use cases, and CUDA (the language and execution of that language) will manage memory between the CPU and GPU without direct programmer oversight. Unified memory, with some thanks to the 49-bit virtual memory addressing in Pasal, is able to support operations that exceed total unified memory size by performing operations out-of-core.
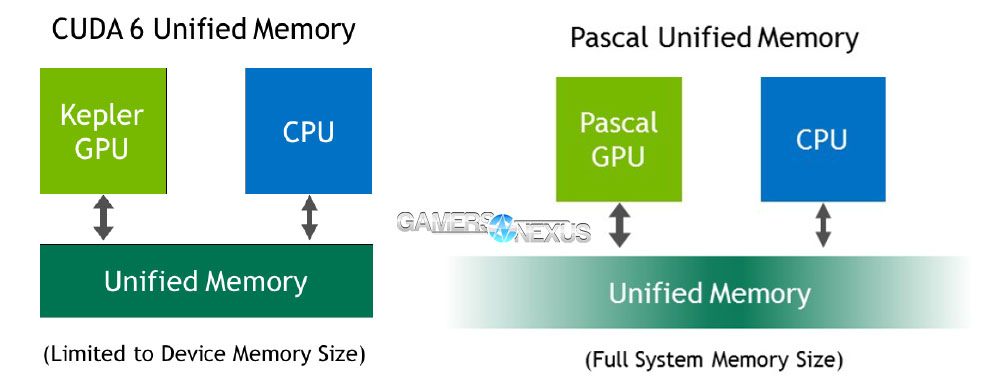
Direct Memory Access for GPUs
Sort of comparable to DMA, GPUDirect and RDMA allow an interchange of data between multiple GPUs. These GPUs can be installed in a single system or across a network (with a sufficiently high-speed line), and are able to directly access the memory of other in-system GPUs for more efficient management of memory. GP100 doubles RDMA bandwidth with some specific gains for deep learning. We'll leave this aspect here for today, and will explore in greater depth in a forthcoming piece. RDMA and GPUDirect begin to exit the scope of this content.
Pascal Memory Subsystem – HBM 1 vs. HBM 2

(Above: Cross-section of GP100 & HBM2)
AMD's Fiji (Fury X) was the first GPU to use HBM, or high-bandwidth memory. Rather than rely upon the tremendously slower, PCB-bound GDDR5 memory of traditional GPUs, Fiji hosted its memory atop an interposer, which sat atop the substrate.
HBM in Fiji – and in GP100, though we'll get there soon – is stacked vertically. Physical distance between the graphics processor and memory is reduced, the bus is wider, and the electrical and thermal requirements are better controlled. HBM is better in every performance metric and falls behind only in cost and yield (for HBM2 especially). GDDR5 pushes a maximum theoretical throughput of about 8Gbps, with Micron's upcoming GDDR5X improving speeds ~47% to 13-14Gbps.
Each stack of HBM has a 1024-bit wide interface per stack, or 128GB/s throughput per stack. HBM can support 2Gb per die maximally. GDDR5 operates at ~28GB/s per chip. Due to restrictions and yields, Fiji was unable to offer more than 4GB of HBM, a severe limitation as games continue to push more textures and assets to VRAM and seem to care more about capacity than speed.
HBM2 makes significant changes from HBM “1.” With HBM2, relevant Pascal devices like the GP100 will be able to maximally host 16GB of VRAM pursuant to increased die density of the new version. HBM2 densities run upwards of 8Gb with 4-8 dies per GPU, maximally enabling the 16GB capacity (though initial P100 Accelerator shipments will be 8GB). Here is a simple table:
| HBM1 | HBM2 | |
| Density | 2Gb DRAM | 8Gb DRAM |
| Stack Density | 4 dies per stack | 4-8 dies per stack |
| Bandwidth | 125GB/s | 180GB/s |
Pascal GP100 currently builds its HBM2 memory as a composition of five dies, but presents a coplanar surface so that heatsink mounting and hotspot cooling remain somewhat simple. The dies include the base die and the stacked DRAM above it. This sits atop a passive silicon interposer, as does the GP100 GPU, and all of that sits on the substrate.

GP100 has a 4096-bit wide memory interface for its HBM2 memory, resultant of dual 512-bit memory interfaces running between the stacks. HBM2 additionally offers native ECC (Error Checking & Correction) for parity-bit checking and on-the-fly recovery of erroneous data, useful for performance applications and cluster computing. This functions differently on Pascal than Kepler GK110, where 6.25% of GDDR5 was reserved for ECC bit checking. With HBM2 and GP100, this function is offered natively and without a “reserve” of capacity.
Industry Trends Forward & Gaming Needs


We're still awaiting GeForce announcements, but this early look at Pascal's existing GP100 GPU – although it is intended entirely for use in the scientific community – provides us with an architectural understanding of the processor. It is likely that not all of the Pascal GPUs will include the featureset defined herein, but the SM architecture and basics should remain the same. HBM2 is likely to be a “swappable” aspect for low-end devices and may mean a mix of GDDR5, GDDR5X, and HBM2 graphics cards. COMPUTE Preemption is also less useful for gaming, as are some of the other error checking features, and will be entirely unadvertised or excluded from GeForce-class chips.
The industry is trending toward faster, closer DRAM for the GPU. HBM was the start, and HBM2 carries that torch. It is yields and cost that hold-back proliferation of high-bandwidth memory, but Micron's GDDR5X (if it catches on) will offer an improvement over GDDR5 at a lower cost than HBM.
The rest of the major improvements come in the form of performance-per-watt gains through die shrinks made by TSMC (16nm FinFET vs. 28nm planar). AMD is making its own die shrinks to 14nm FinFET with Polaris, and will exact its own performance-per-watt gains as a result of this.
The industry, especially the mobile industry, dictates reduced power consumption overall but demands that reduction without significant performance compromise. It looks as if Pascal will be able to achieve that – and more, for the scientific community. We have a few more pieces we're planning to post on Pascal and neighboring nVidia technologies, so be sure to add us to your RSS feed, facebook feed, or Twitter / YouTube lists.
Editorial: Steve “Lelldorianx” Burke
Forthcoming Video Production: Keegan “HornetSting” Gallick